Logged in as an admin user, use the left-hand navigation menu to select “Security”. Select “Tenants” and click on “Create tenant”.
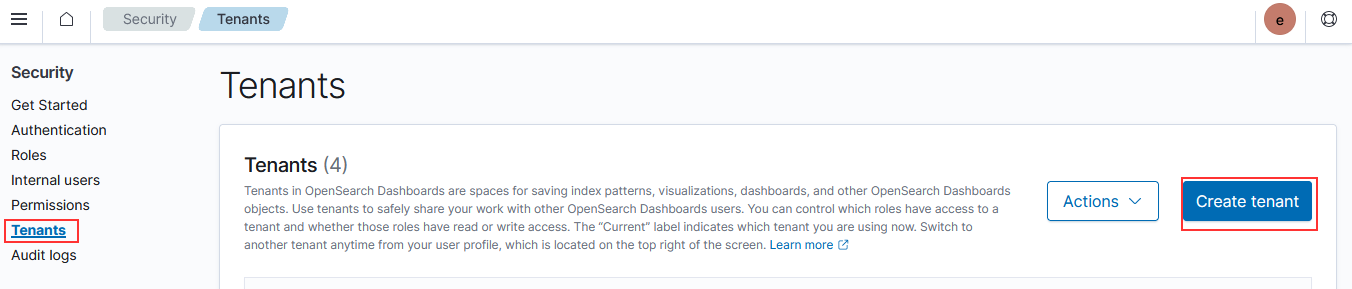
Give the tenant a name and a description, then click “Create”
OK, now a tenant is created. The important bit is to establish a role that only sees data within the tenant. Click on “Roles”, then click “Create role”.
Give the role a name:
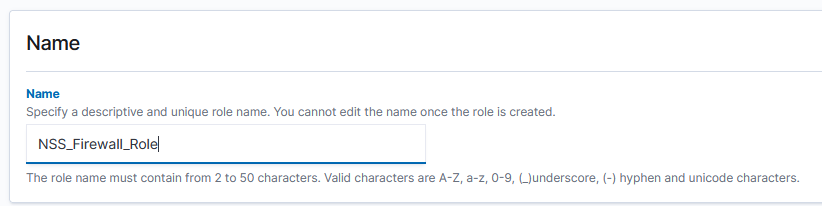
Under “Cluster permissions” add either cluster_composite_ops_ro (for read only access – cannot make new visualizations or dashboards) or cluster_composite_ops – we may make a “help desk” type role where users are not permitted to write to the tenant, but my examples herein are all for business owners who will be able to save queries, create visualizations, modify dashboards, etc.
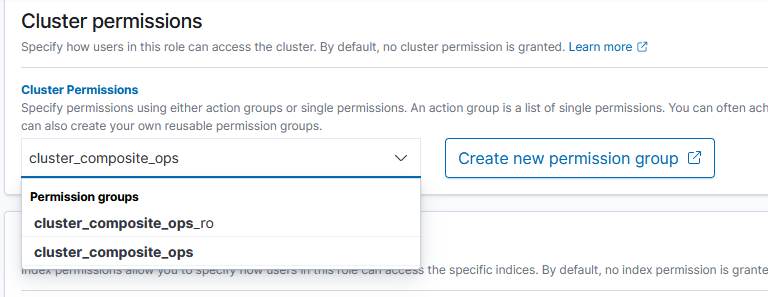
Under “Index permissions”, add the index pattern (or patterns) to which the tenant should have access. Add read or read/write permissions to the index. We are not using any of the fine-grained security components (providing access only to records that come in from a specific host or contain a specific error)
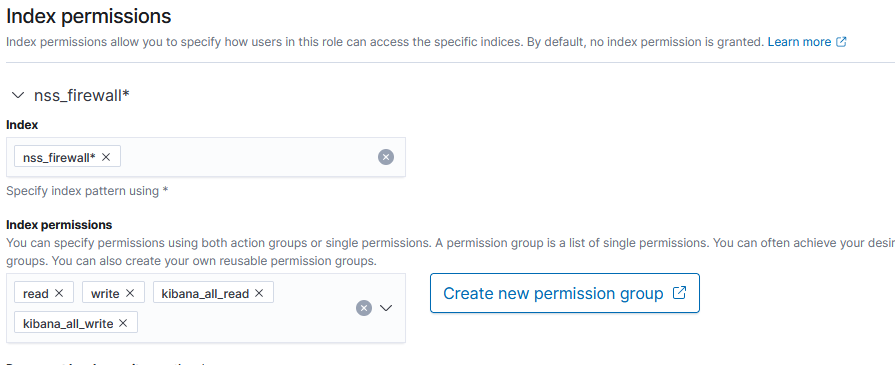
Finally, under “Tenant Permissions”, select the associated tenant and grant either Read or Read and Write permission
Click “Create” and your new role has been created. Once created, click on “Mapped users”
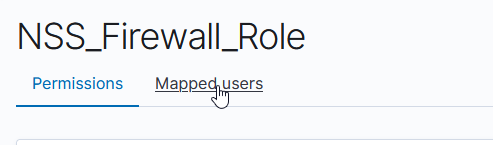
Select “Map users” to edit the users mapped to the role.
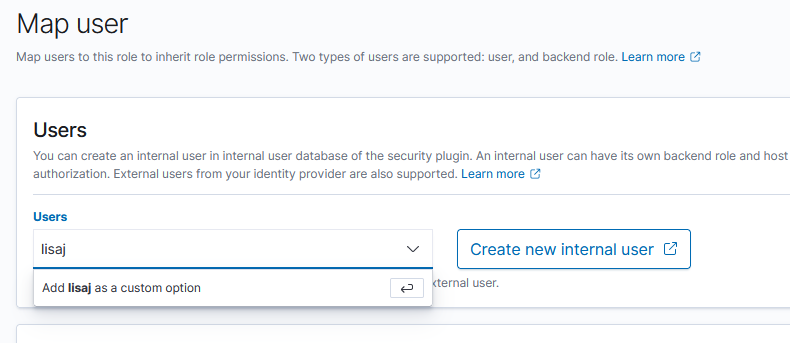
To map an externally authenticated user (accounts authenticate through OpenID, for example), just type the username and hit enter to add “as a custom option”.
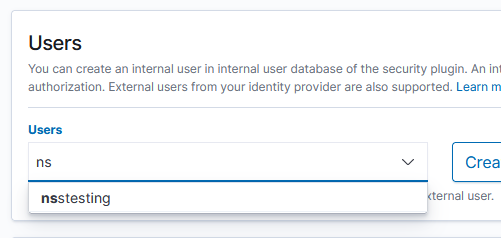
For an internal user, you’ll be able to select them from a user list as you begin typing the user ID
There is one trick to getting a new tenant working — https://forum.opensearch.org/t/multi-tenancy-for-different-indices/5008/8 indicates you’ve got to use an admin account from the global tenant, switch to the new tenant, and create the index pattern there. Once the index pattern (or, I suppose, patterns) has been created, the tenant users are able to discover / visualize their data.
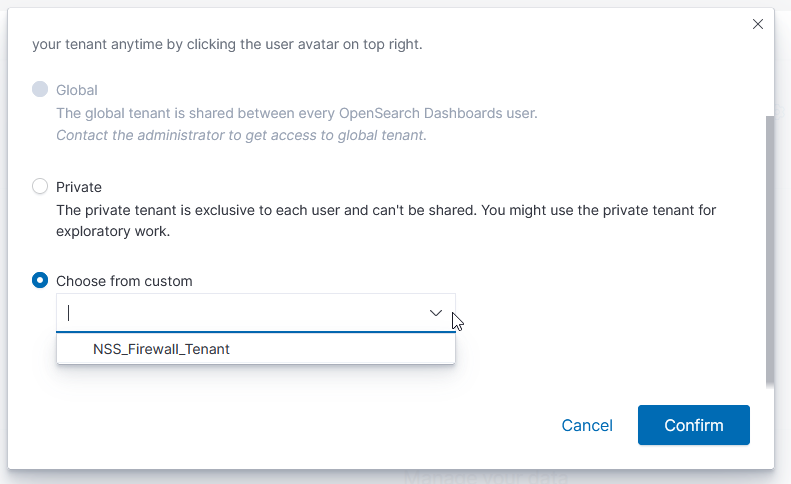
Click on the icon for your user account and select “Switch tenants”
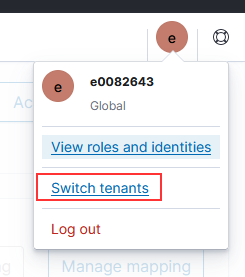
Select the radio button in front of “Choose from custom” and then use the drop-down to select your newly created tenant. Click “Confirm” to switch to that tenant.
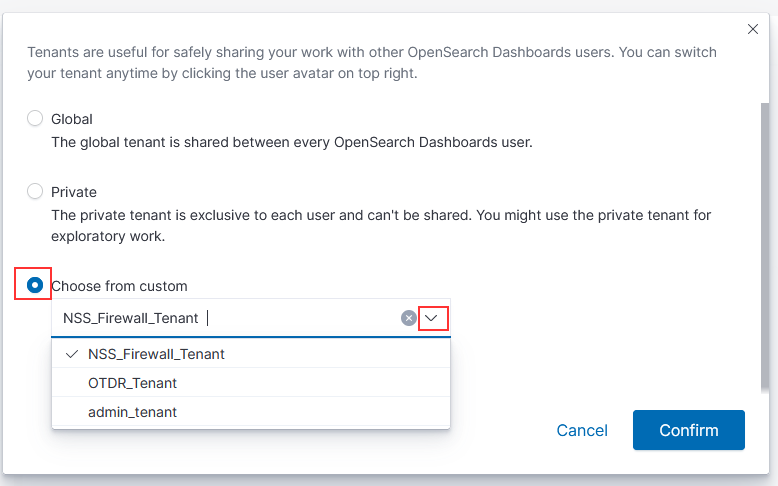
From the left-hand navigation menu, select “Stack Management” and then select “Index Patterns”. Click to “Create index pattern”
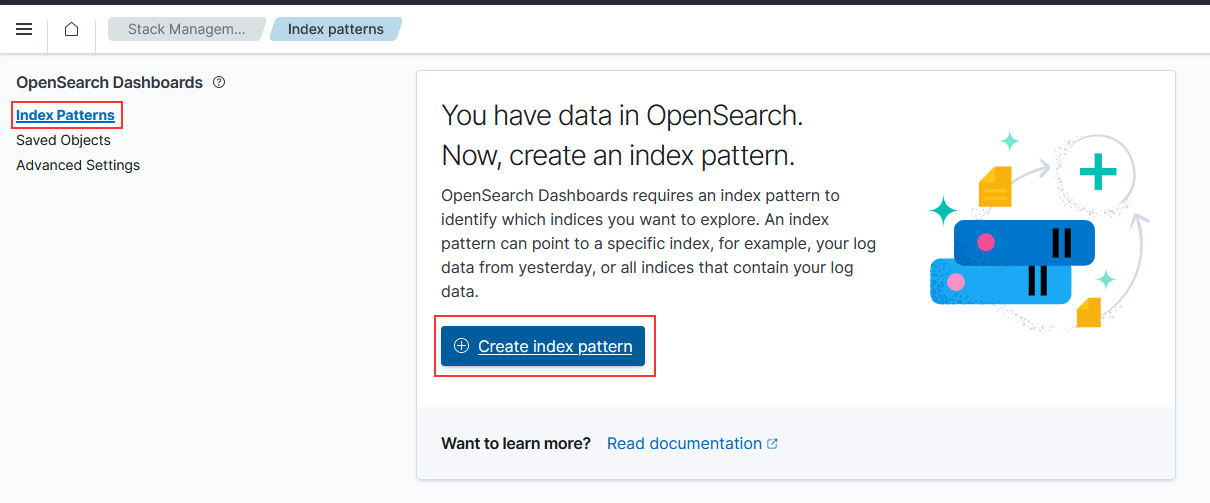
Type the pattern and click “Next step”
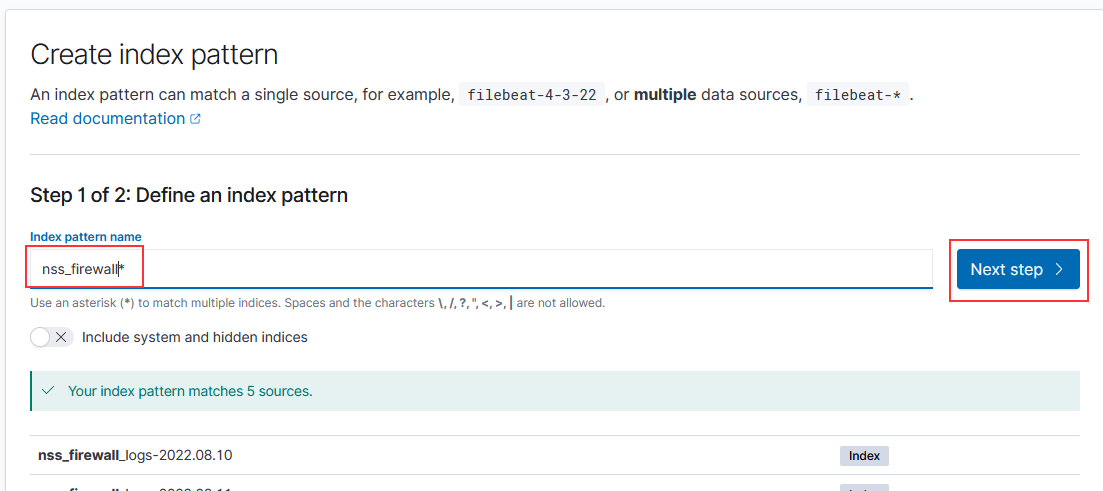
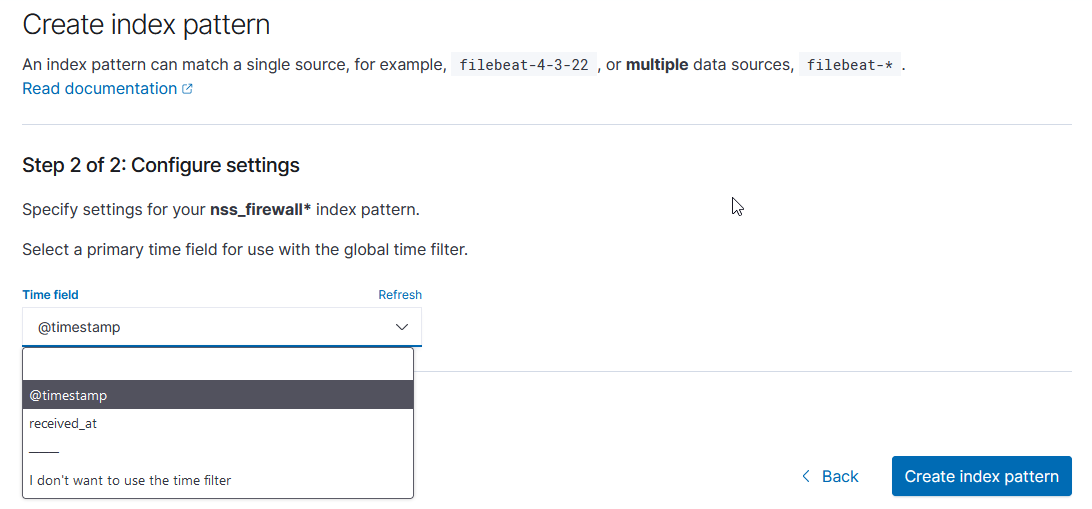
Select the time field from the drop-down menu, then click “Create index pattern”
Now you’re ready – have a user log into OpenSearch Dashboard. They’ll need to select the radio button to “Choose from custom” and select their tenant from the dropdown menu.