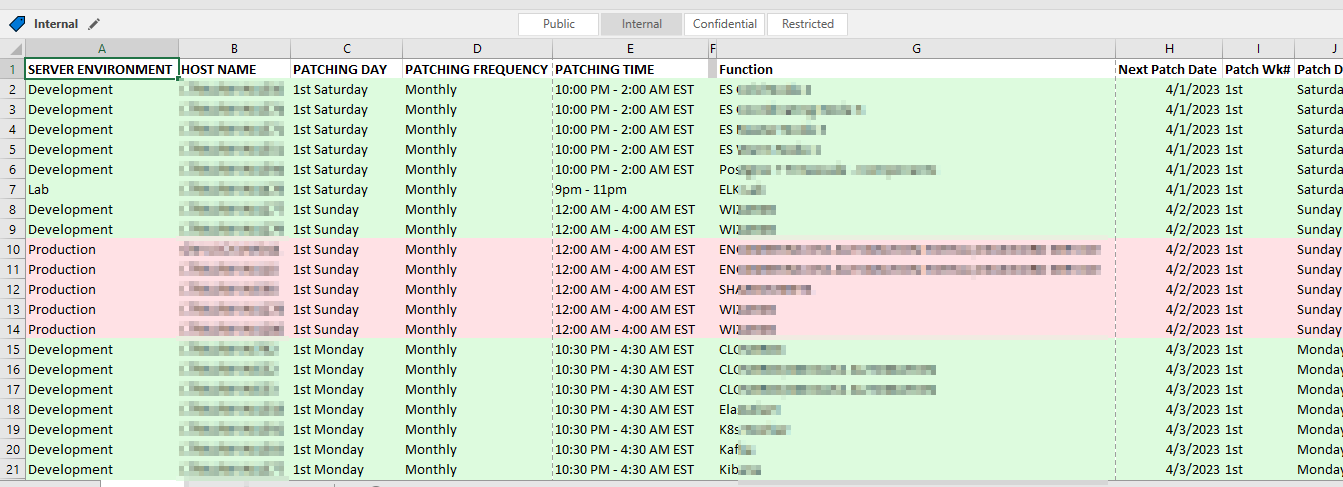
Our patching schedules are algorithmic – the 1st Tuesday of the month, the 3rd Wednesday of the month, etc. But that’s not particularly useful for notifying end users or for us to verify functionality after patching.
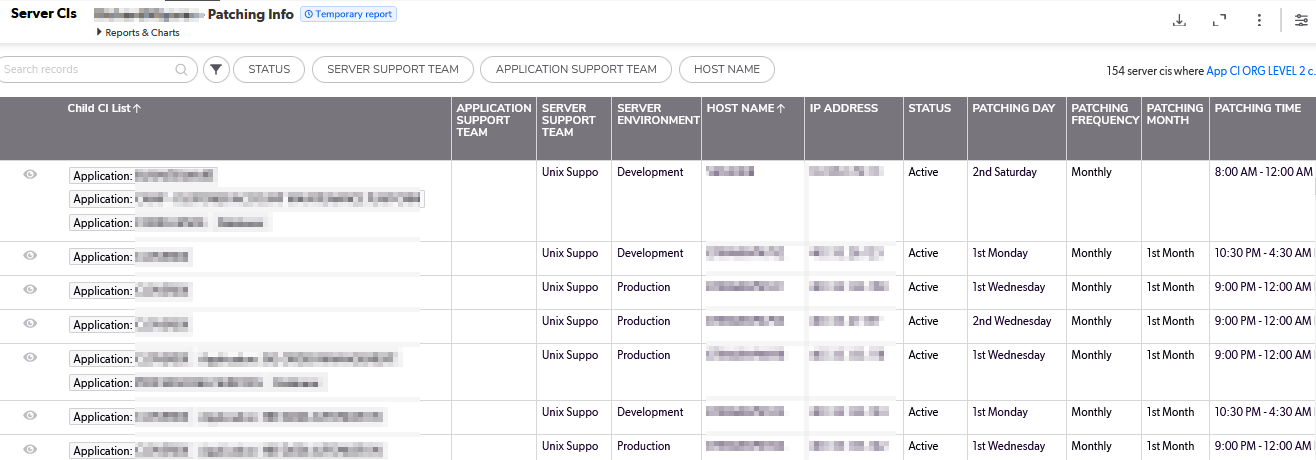
Long term, I think we can pull the source data from a database and create appointment items each month for whatever list of servers will be patched that month based on a relative date (so no one has to add new servers or remove decommissioned servers). But, short term? I really wanted a way to see what date a server would be patched. So I created a but of a convoluted spreadsheet to produce this information based on a list of servers and patching schedule patterns.
There are two “extra” tabs used – “Dates” used to say what month and year I want the patching dates for
And “ServerData” which provides a cross-reference between the server names and a useful description.
There are then a series of formulae used to add columns to our source data. First, the “Function” is populated in column G with a VLOOKUP =VLOOKUP(B2,ServerData!A:B,2,FALSE)
Columns I and J break the “1st Saturday” into the two components – week of month and day of week –
I =LEFT(C2,3)
J =RIGHT(C2,LEN(C2)-4)
Columns K and L then map these components into numeric values I can use in a formula:
K =IF(I2=”1st”,1,IF(I2=”2nd”,2,IF(I2=”3rd”,3,IF(I2=”4th”,4,”Unscheduled”))))
L =IF(J2=”Sunday”,1,IF(J2=”Monday”,2,IF(J2=”Tuesday”,3,IF(J2=”Wednesday”,4,IF(J2=”Thursday”,5,IF(J2=”Friday”,6,IF(J2=”Saturday”,7,”Unscheduled”)))))))
And finally a formula in column H that turns the week of month and day of week values into an actual date within the month and year on the “Dates” tab:
H =DATE(Dates!$B$2,Dates!$A$2,1+7*K2)-WEEKDAY(DATE(Dates!$B$2,Dates!$A$2,8-L2))
Voila – I have a spreadsheet that says we should expect to see this specific list of servers being patched tonight.