I took the cart for a walk and dug up some of the really rich dirt from the forest floor … this will be our seed starting soil for the year.

I took the cart for a walk and dug up some of the really rich dirt from the forest floor … this will be our seed starting soil for the year.
We used our DigiBoil 65L 240V pot to finish the sap since it’s quick to remove from the heat once the syrup is ready (and it’s got a spigot that makes emptying the pot easier). This also gave us a good picture of how long the DigiBoil is going to take to boil wort when we’re making beer. Yesterday, with temps in the upper 30’s, it took about 1h50m (basically two hours) to boil 10 gallons of concentrated sap. Today, with temps in the upper 40’s, it took about 50 minutes to boil 7 gallons of concentrated sap.
Sunday 05 March 2023
15:44 59F
16:40 167F
17:17 203F
17:34 208F and rapidly boiling
1h50m to boil.
Flamed out just after midnight
Monday 06 March 2023
09:43AM – 68F turned on 500W
09:50AM – Turned on 2nd switch
09:56AM – 111F – turned on 3rd switch
10:32AM – 7 gallons is now boiling
About 50 minutes to boil.
Maple flame out at 2:34PM
Bottled, we have 3.5 gallons of maple syrup from our first run

Anya was playing around with some artistic photography today — duck reflections in the pond.

I’ve said about social media type platforms – if you are making an informed decision to trade privacy for convenience / information / entertainment / comradery … if you feel that you are getting a good “deal” in that trade? Then social media type platforms are awesome. If you only think you are getting something in the deal – unaware of what the platform owners are getting from you – then I find that problematic.
The same is true for the public AI models – some of what they are getting from you is just language training & beta testing. If I had a dozen people type questions, I have not gotten a robustly representative sample of how ‘people’ talk. Getting a few million people to provide samples of their linguistic quirks is absolutely an important part of producing universally useful natural language processing. The models are also asking you to flag anything odd / wrong / unsettling. Again, this is the public providing numbers to testing that has already been done.
But … if an AI is being trained by inputs, information you provide is being incorporated into the underlying patterns. Which isn’t to say they are saving the exact text I provided in a transaction. Even so, the information provided can, in a more general sense, become part of the AI’s knowledge base. And, if that knowledge base is used to serve results to the general public? Then it is possible for the AI to “leak” confidential information that I fed into transactions.
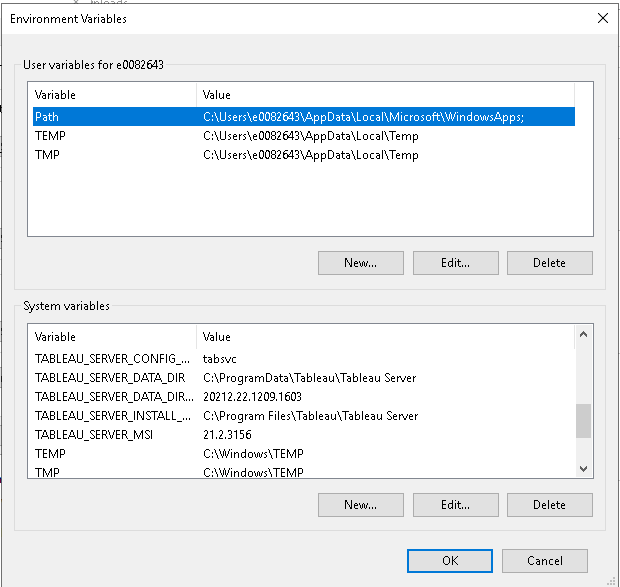
When attempting to install Tableau, I got an error telling me that “an older version of tableau is installed but the tsm administrative services are not running” … which, as I didn’t own the server until recently, was quite possibly true. But it was also uninstalled from the control panel, cleaned up on disk, and really not there to start.
I discovered that Tableau registers some environment variables — and the mere presence of these variables will cause the “it’s already installed, so I’m not going any farther” error. Deleting the environment variables allowed me to re-install the current Tableau version without problem.
To remove an environment variable, go to Control Panel > System > Advanced system settings — highlight the variable you want to remove (all of the TABLEAU* ones in this case) and click ‘Delete’.
I cannot say it surprises me that a company that considered “restart it” and “reboot it” to be suitable solutions to a whole host of memory management issues has decided that clearing the history after n interactions with their AI chatbot is the solution to not having it out looking for nuclear codes. From a functional standpoint, I can see where one or two “turns” is probably sufficient for the search engine to produce some salient information or relevant links. But, from a technological standpoint, it seems that an AI that becomes “confused” five or six exchanges into a conversation is vastly problematic; and introducing some artificial limit on the front-end to reset the history (1) eliminates a key feature of learning algorithms by preventing it from “learning” you and (2) is akin to turning your back on a tiger and considering the problem sorted.

So far, we’ve collected about 121 gallons of maple sap. We started boiling the sap on the 23rd using our new maple evaporator.
Maple Sap Collection Log
| Date | Location | Quantity |
| 2/14/2023 | All trees except river | 60 |
| 2/18/2023 | All trees except river | 20 |
| 2/23/2023 | All trees except river | 15 |
| 2/25/2023 | River | 6 |
| 2/26/2023 | Back woods and front yard | 12 |
| 2/26/2023 | Top of Driveway – east and west | 8 |
We spent some time clearing a path to the maple trees — not wading through privet makes collecting sap a lot easier! Anya found some moss she really liked, and she wants to propagate it in a moist, shady spot by the house.

We built our maple evaporator — well, combination fire table, maple evaporator, grill, and smoker all-in-one backyard fire contraption. Scott calls it the MapleAtor. Total cost was about a hundred bucks — $60 for refractory brick, about $10 for the cinder blocks, and about $30 for “engineering” size brick (and probably another hundred bucks in fuel to *get* the blocks and refractory brick!).
We’ve got a layer of cinder blocks on the base — four rows five blocks long. Since we had four half-blocks, we were able to stagger the walls. Nothing is mortared together yet — we wanted to make sure it was a good size, shape, and location before we made anything permanent.
Two rows of fire brick lay atop the cinder blocks — we wanted to be able to set the 6″ steam table trays that we use to evaporate sap onto the cinder blocks and seal the fire section in so the syrup doesn’t get smoked as we evaporate it. The dimensions didn’t quite line up — we needed something 2 3/4″ high to fill in the gap between the edge of the refractory brick and the edge of the cinder block. I happened across “engineering” bricks online, and we found a company that sold them. They fit perfectly.

Once the base layer was covered in refractory brick and red brick, we started stacking the walls — more cinder blocks.

Along the back wall, we have some bricks forming a wall, but we have one row slightly pushed in so a block can straddle the two bricks and form an exhaust area. Then a bunch of blocks are stacked up to form a chimney.
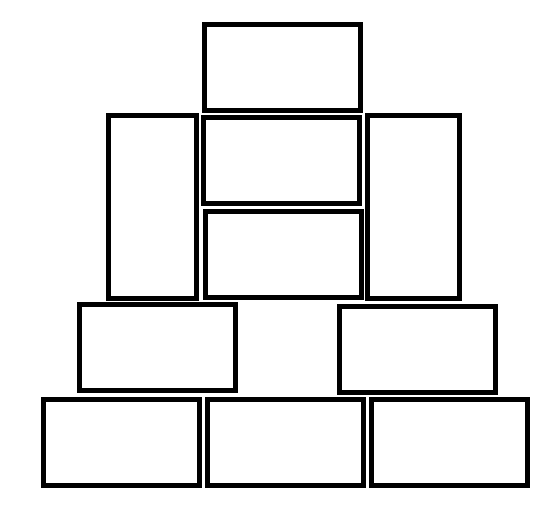
The evaporator trays fit perfectly and are supported by the cinder block.

We ended up re-stacking the chimney — having the exhaust port at the same level as the refractory brick meant that pushing wood around in the fire box shoved coals out into the chimney. The exhaust port is now one row higher than pictured.

We then lined the firebox with more refractory brick — there are two or three inches between the top of the refractory brick and the bottom of the evaporator trays. Adding logs and lighting a fire, we finally have maple sap evaporating.

We added a steel plate at the end of the trays to keep smoke away from the sap.

Bonus — we can cook dinner while we’re evaporating sap!

