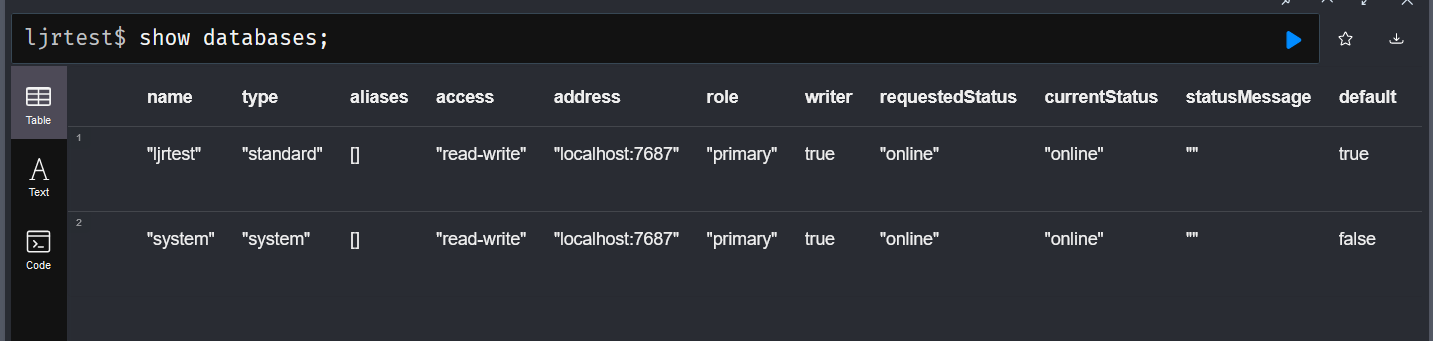
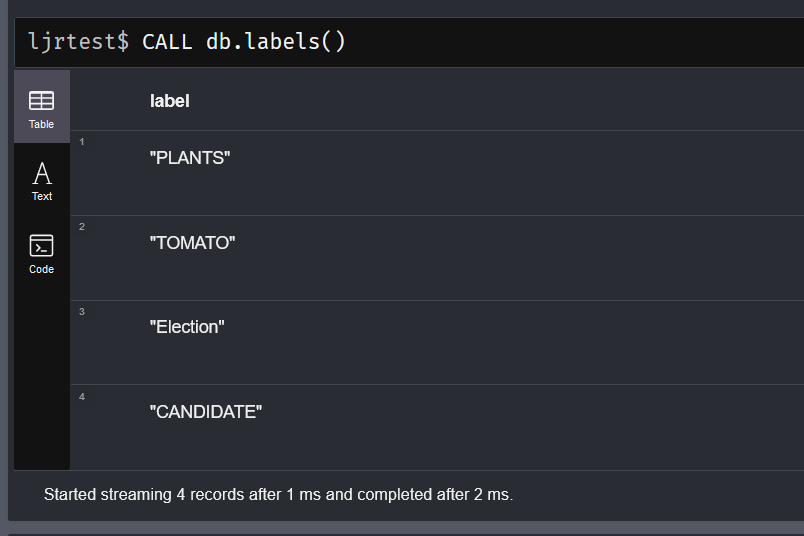
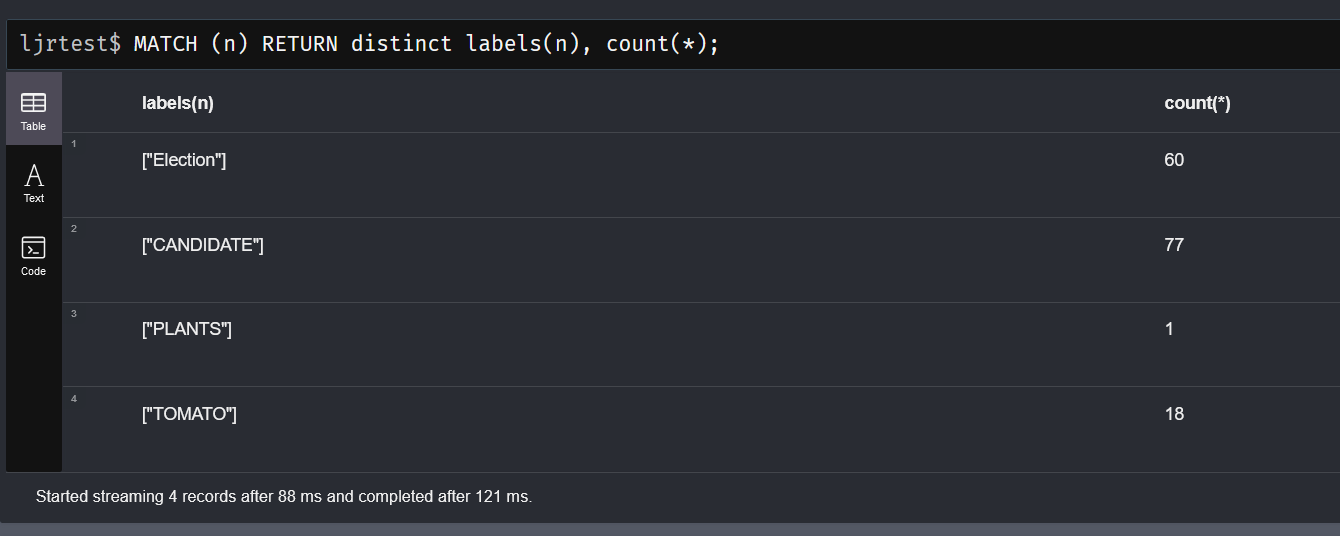
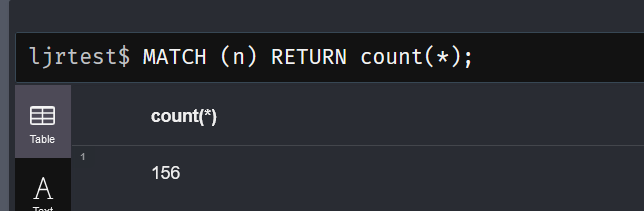
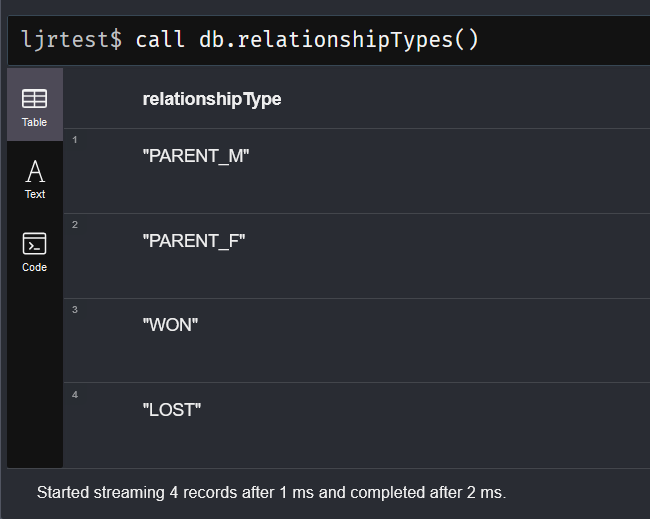
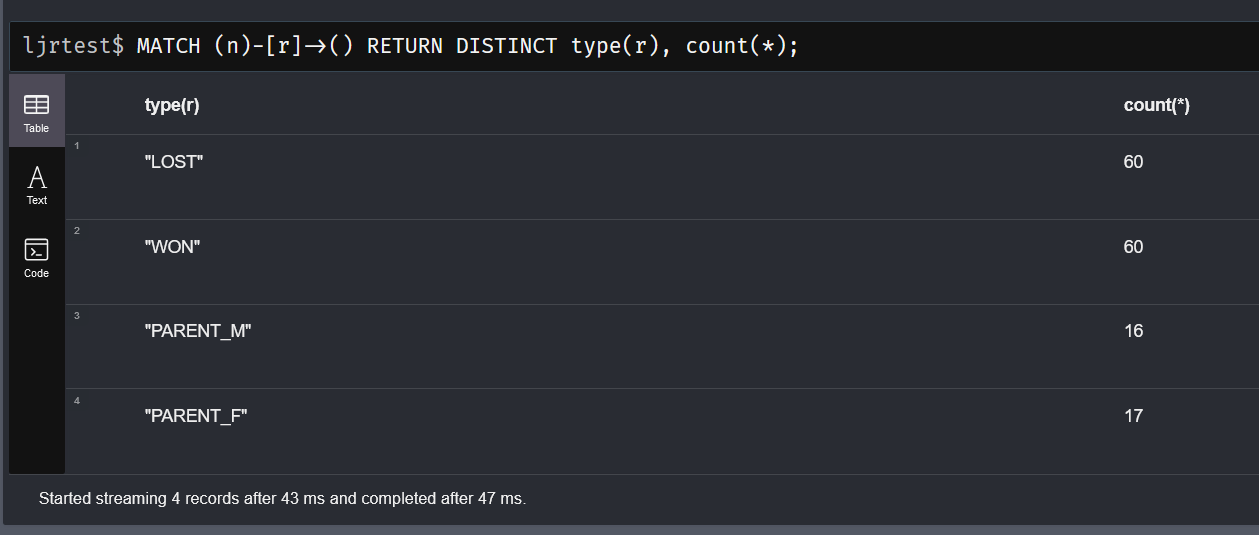
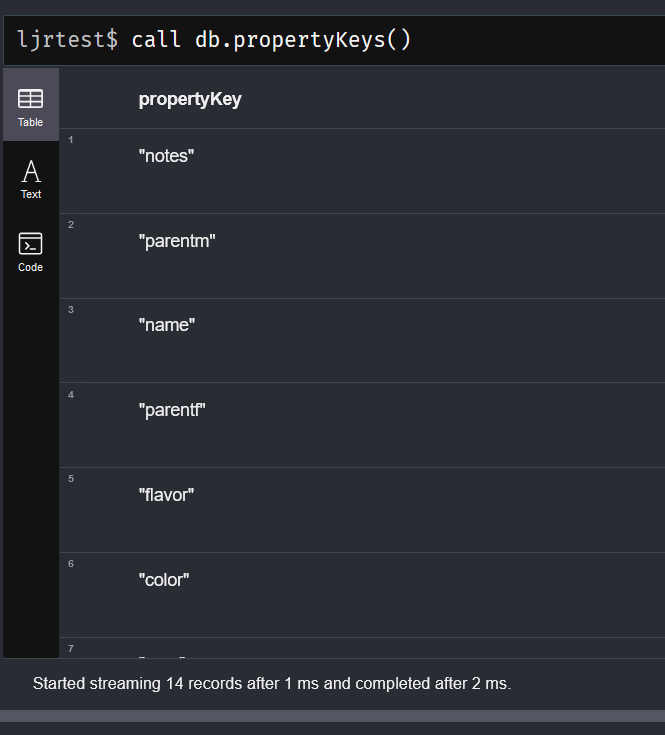
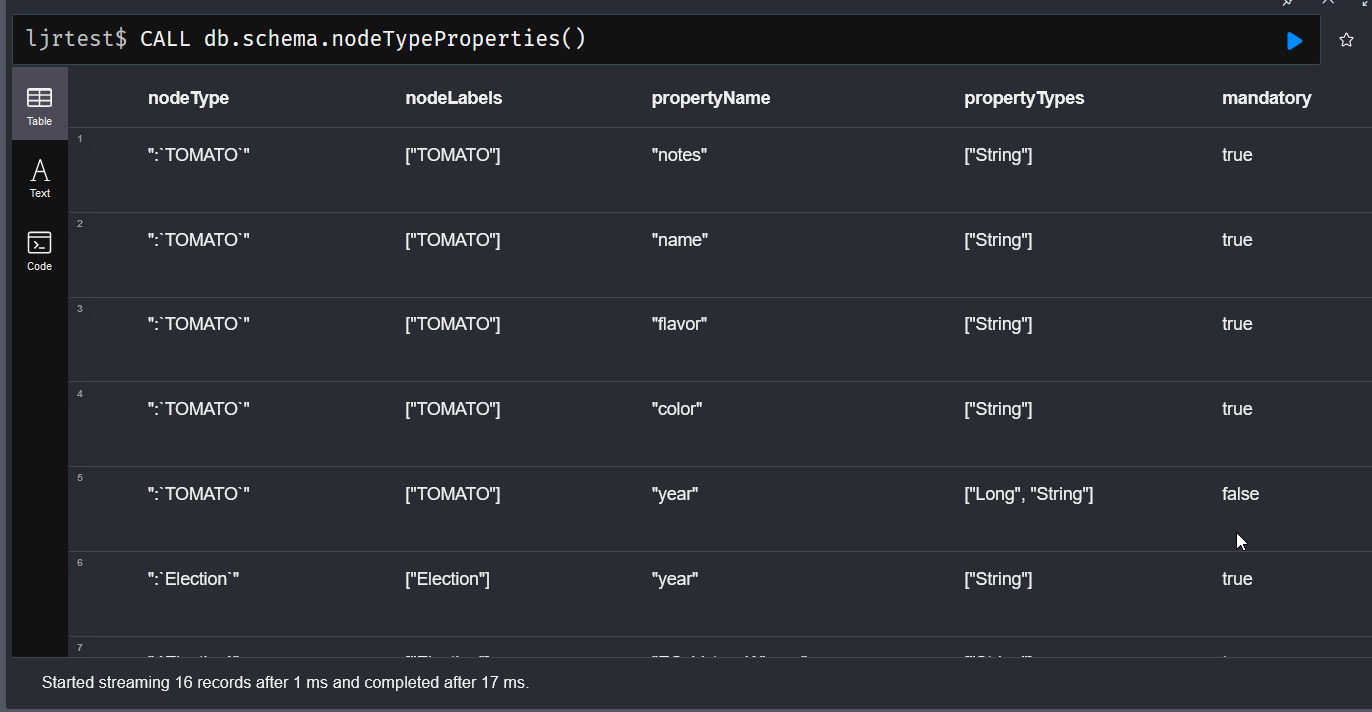
We inherited a system that uses MongoDB, and I managed to get the sandbox online without actually learning anything about Mongo. The other environments, though, have data people care about set up in a replicated cluster of database servers. That seems like the sort of thing that’s going to require knowing more than “it’s a NoSQL database of some sort”.
It is a NoSQL database — documents are organized into ‘collections’ within the database. You can have multiple databases hosted on a server, too. A document is a group of key/value pairs with dynamic schema (i.e. you can just make up keys as you go).
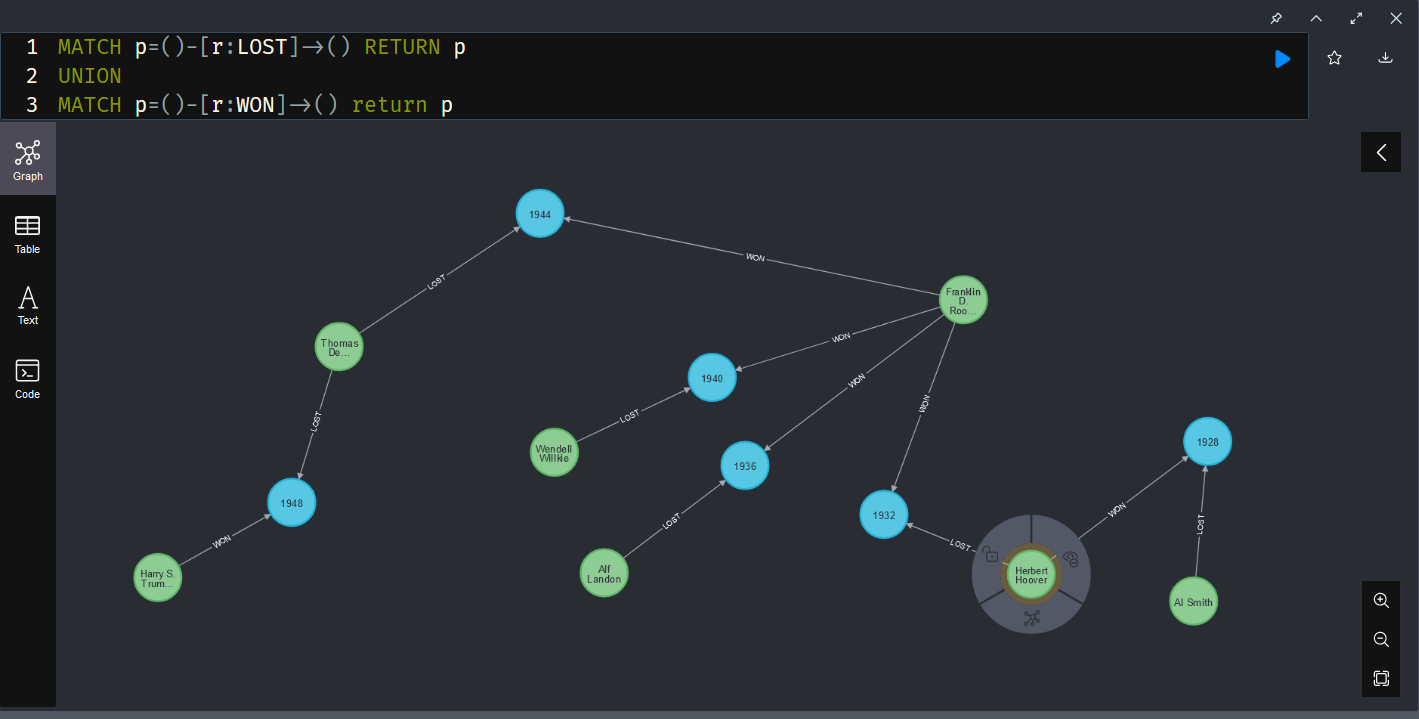
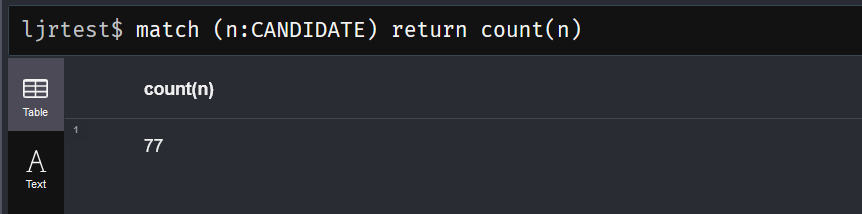
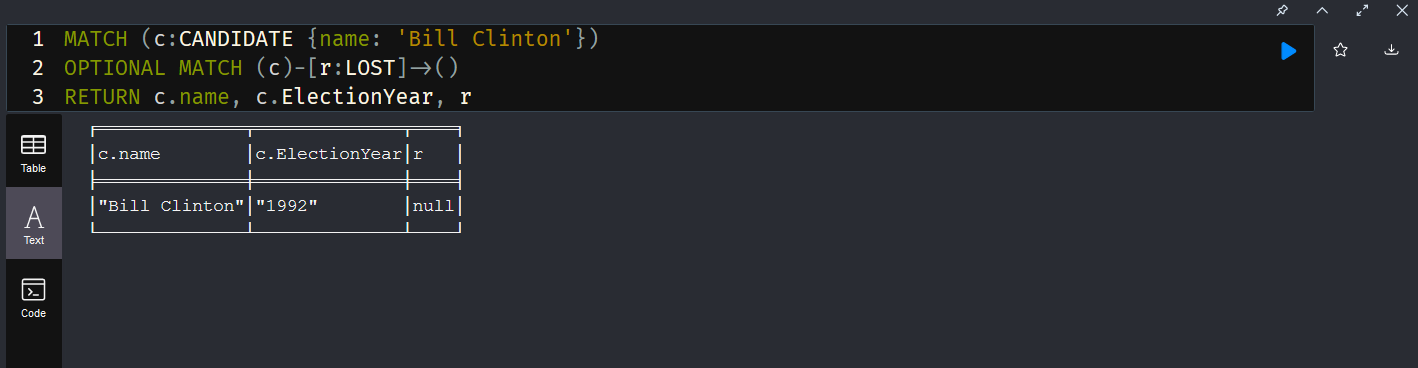
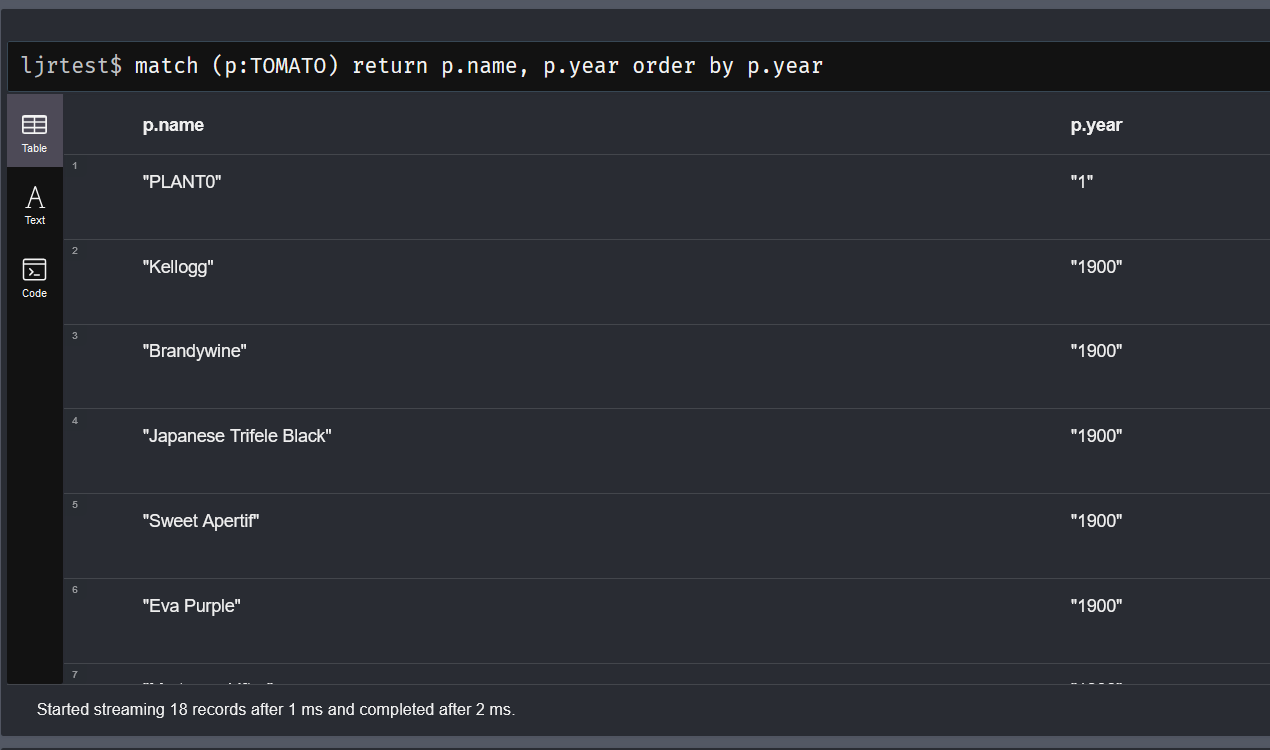
There are GUI clients and a command-line shell … of course I’m going with the shell 🙂 There is a db function for basic CRUD operations using db.nameOfCollection then the operation type:
db.collectionName.insert({"key1": "string1", "key2" : false, "key3": 12345})
db.collectionName.find({key3 : {$gt : 10000} })
db.collectionName.update({key1 : "string1"}, {$set: {key3: 100}})
db.collectionName.remove({key1: "string1"});
CRUD operations can also be performed with NodeJS code — create a file with the script you want to run, then run “node myfile.js”
Create a document in a collection
var objMongoClient = require('mongodb').MongoClient;
var strMongoDBURI = "mongodb://mongodb.example.com:27017/";
objMongoClient.connect(strMongoDBURI, function(err, db) {
if (err) throw err;
var dbo = db.db("dbNameToSelect");
var objRecord = { key1: "String Value1", key2: false };
dbo.collection("collectionName").insertOne(objRecord, function(err, res) {
if (err) throw err;
console.log("document inserted");
db.close();
});
});
Read a document in a collection
var objMongoClient = require('mongodb').MongoClient;
var strMongoDBURI = "mongodb://mongodb.example.com:27017/";
objMongoClient.connect(strMongoDBURI, function(err, db) {
if (err) throw err;
var dbo = db.db("dbNameToSelect");
var objQuery = { key1: "String Value 1" };
dbo.collection("collectionName").find(objQuery).toArray(function(err, result) {
if (err) throw err;
console.log(result);
db.close();
});
});
Update a document in a collection
var objMongoClient = require('mongodb').MongoClient;
var strMongoDBURI = "mongodb://mongodb.example.com:27017/";
objMongoClient.connect(strMongoDBURI, function(err, db) {
if (err) throw err;
var dbo = db.db("dbNameToSelect");
var objRecord= { key1: "String Value 1" };
dbo.collection("collectionName").deleteOne(objRecord, function(err, obj) {
if (err) throw err;
console.log("Record deleted");
db.close();
});
});
Delete a document in a collection
var objMongoClient = require('mongodb').MongoClient;
var strMongoDBURI = "mongodb://mongodb.example.com:27017/";
objMongoClient.connect(strMongoDBURI, function(err, db) {
if (err) throw err;
var dbo = db.db("dbNameToSelect");
var objQuery = { key1: "String Value 1" };
var objNewValues = { $set: {key3: 12345, key4: "Another string value" } };
dbo.collection("collectionName").updateOne(objQuery, objNewValues , function(err, res) {
if (err) throw err;
console.log("Record updated");
db.close();
});
});