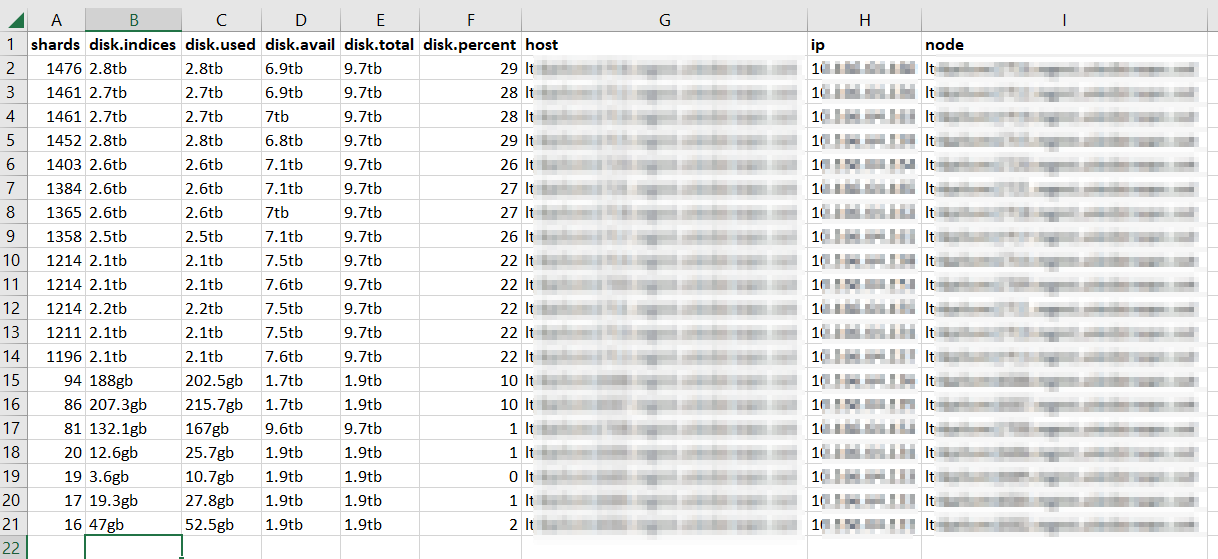
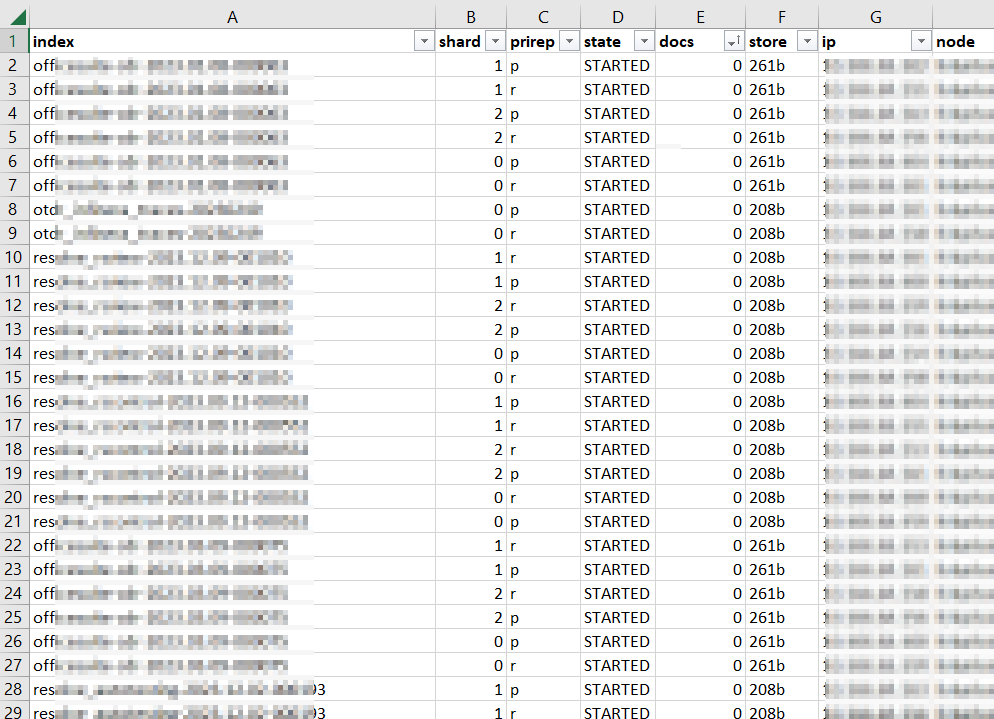
One of the trickier bits of migrating from ElasticSearch to OpenSearch has been the local users — most of our users are authenticated via OAUTH, but programmatic access is done with local user accounts. Fortunately, you appear to be able to get the user password hash from the .opendistro_security API if you authenticate using an SSL cert.
This means the CN of the certificate being used must be registered in the elasticsearch.yml as an admin DN:
plugins.security.authcz.admin_dn:
- 'CN=admin,O=LJRTest,ST=Ohio,C=US'
- 'CN=ljradmin,O=LJRTest,ST=Ohio,C=US'
Provided the certificate is an admin_dn, the account can be used to search the .opendistro_security index and return local user info — including hashes. Information within the document is base 64 encoded, so the value needs to be decoded before you’ve got legible user information. One the user record has been obtained, the information can be used to POST details to the OpenSearch API and create a matching user.
import json
import requests
import base64
from requests.auth import HTTPBasicAuth
clientCrt = "./certs/ljr-mgr.pem"
clientKey = "./certs/ljr-mgr.key"
strOSAdminUser = 'something'
strOSAdminPass = 'something'
r = requests.get("https://elasticsearch.example.com:9200/.opendistro_security/_search?pretty", verify=False, cert=(clientCrt, clientKey))
if r.status_code == 200:
dictResult = r.json()
for item in dictResult.get('hits').get('hits'):
if item.get('_id') == "internalusers":
strInternalUsersXML = item.get('_source').get('internalusers')
strUserJSON = base64.b64decode(strInternalUsersXML).decode("utf-8")
dictUserInfo = json.loads(strUserJSON)
for tupleUserRecord in dictUserInfo.items():
strUserName = tupleUserRecord[0]
dictUserRecord = tupleUserRecord[1]
if dictUserRecord.get('reserved') == False:
dictUserDetails = {
"hash": dictUserRecord.get('hash'),
"opendistro_security_roles": dictUserRecord.get('opendistro_security_roles'),
"backend_roles": dictUserRecord.get('backend_roles'),
"attributes": dictUserRecord.get('attributes')
}
if dictUserRecord.get('description') is not None:
dictUserDetails["description"] = dictUserRecord.get('description')
reqCreateUser = requests.put(f'https://opensearch.example.com:9200/_plugins/_security/api/internalusers/{strUserName}', json=dictUserDetails, auth = HTTPBasicAuth(strOSAdminUser, strOSAdminPass), verify=False)
print(reqCreateUser.text)
else:
print(r.status_code)