This turned out to be one of those situations where I went down a very complicated path for a very simple problem. We were setting up ElastAlert2 in our OpenSearch sandbox. I’ve used both the elasticsearch-py and opensearch-py modules with Python 3 to communicate with the cluster, so I didn’t anticipate any problems.
Which, of course, meant we had problems. A very cryptic message:
javax.net.ssl.SSLHandshakeException: Insufficient buffer remaining for AEAD cipher fragment (2). Needs to be more than tag size
A quick perusal of the archive of all IT knowledge (aka Google) led me to a Java bug: https://bugs.openjdk.org/browse/JDK-8221218 which may or may not be resolved in the latest OpenJDK (which we are using). I say may or may not because it’s marked as resolved in some places but people report experiencing the bug after resolution was reported.
Fortunately, the OpenSearch server reported something more useful:
[2022-09-20T12:18:55,869][WARN ][o.o.h.AbstractHttpServerTransport] [UOS-OpenSearch.example.net] caught exception while handling client http traffic, closing connection Netty4HttpChannel{localAddress=/10.1.2.3:9200, remoteAddress=/10.1.2.4:55494} io.netty.handler.codec.DecoderException: io.netty.handler.ssl.NotSslRecordException: not an SSL/TLS record: 504f5354202f656c617374616c6572745f7374617475735f6572726f722f5f646f6320485454502f312e310d0a486f73743a20
Which I’ve shortened because it was several thousand fairly random seeming characters. Except they aren’t random — that’s the communication hex encoded. Throwing the string into a hex decoder, I see the HTTP POST request.
Which … struck me as rather odd because it should be SSL encrypted rubbish. Turns out use_ssl was set to False! Evidently attempting to send clear text ‘stuff’ to an encrypted endpoint produces the same error as reported in the Java bug.
Setting use_ssl to true brought us to another adventure — an SSLCertVerificationError. We have set the verify_certs to false — even going so far as to go into util.py and modifying line 354 so the default is False. No luck. But there’s another config in each ElastAlert2 rule — http_post_ignore_ssl_errors — that actually does ignore certificate errors. One the rules were configured with http_post_ignore_ssl_errors, ElastAlert2 was able to communicate with the OpenSearch cluster and watch for triggering events.
I have a syslog message that contains a null terminated string: "syslog_message":"A10\u0000" — these messages represent is-alive checks from a load balancer to the logstash servers. I would prefer not to have thousands of “the A10 checked & said logstash is still there” filling up Elasticsearch.
Unfortunately, the logstash configuration doesn’t recognize unicode escape sequences … and it’s not like I can literally type a NULL the way I could type a ° or è
I’ve been able to filter out any messages that start with A10. Since our “real” messages start with timestamps, I shouldn’t be dropping any good data, but there’s always the possibility. Without any way to indicate a null character, the closest match is any single character … and I’ve decided not to worry about a possible log message that is simply A101 or A10$ until we encounter a system that would send such messages.
#if [message] == "A10\u0000"{ -- doesn't work
#if [message] == "A10\\u0000"{ -- doesn't work
#if [message] == 'A10\u0000'{ -- doesn't work
#if [message] =~ /^A10/{ -- this isn't great because of false positives, although *these* messages all start with a timestamp so are unlikely to match
if [message] =~ "^A10.$" {
drop { }
}
Using filebeat-7.17.4, we have seen instances where no harvesters will start and no IP communication is established with the logstash servers. Stopping the filebeat service, confirming the process and any associated network ports are closed, and then starting the service does not restore communication. In this situation, we have had to restart the logstash servers and immediately begin to see harvesters spin up in the log files:
2022-09-15T12:02:20.018-0400 INFO [input.harvester] log/harvester.go:309 Harvester started for paths:
[/var/log/network/network.log /opt/splunk/var/log/syslog-ng/*/*.log]
{"input_id": "bf04e307-7fb3-5555-87d5-55555d3fa8d6", "source": "/var/log/syslog-ng/mr01.example.net/network.log",
"state_id": "native::2228458-65570", "finished": false, "os_id": "2225548-64550", "old_source":
"/var/log/syslog-ng/mr01.example.net/network.log", "old_finished": true, "old_os_id": "2225548-64550",
"harvester_id": "36555c83-455c-4551-9f55-dd5555552771"}
I took over management of an ElasticSearch environment that has a lot of configuration inconsistencies. Unfortunately, the previous owners weren’t the ones who built the environment either … so no one knew why ServerX did one thing and ServerY did another. Didn’t mess with it (if it’s working, don’t break it!) until we encountered some users who couldn’t find their data — because, depending on which logstash server information transits, stuff ends up in different indices. So now we’re consolidating configurations and I am going to pull the “right” config files into a git repo so we can easily maintain consistency.
Except … any repository becomes in scope for security scanning. And, really, typing your password in clear text isn’t a wonderful plan. So my first step is using environment variables as configuration parameters in logstash.
The first thing to do is set the environment variables somewhere logstash can use them. In my case, I’m using a unit file that sources its environment from /etc/default/logstash
Once the environment variables are there, enclose the variable name in ${} and use it in the config:
Logstash Config
Restart ElasticSearch and verify the pipeline(s) have started successfully.
The following configuration changes needed to be made to enable federated authentication through OpenIDC using OpenDistro 1.8.0 withElasticSearch 7.7.0 — this presupposes that you have an application properly registered with an OIDC identity provider.
My experience is that the ElasticSearchAPI will allow authentication for local users. Kibana, however, does not — if you want to allow local users to log into Kibana, you’d either need a different Kibana instance (permanently allow local users to access Kibana) or update the kibana.yml to exclude the federated logon stuff & restart the service (temporary workaround when the identity provider has an issue).
ElasticSearch, based on the Lucene search software, is a distributed search and analytics application which ingests, stores, and indexes data. Kibana is a web-based front-end providing user access to data stored within ElasticSearch.
What is OpenSearch?
In short, it’s the same but different. OpenSearch is also based on the Lucene search software, is designed to be a distributed search and analytics application, and ingests/stores/indexes data. If it’s essentially the same thing, why does OpenSearch exist? ElasticSearch was initially licensed under the open-source Apache 2.0 license – a rather permissive free software license. ElasticCo did not agree with how their software was being used by Amazon; and, in 2021, the license for ElasticSearch was changed to Server Side Public License (SSPL). One of the requirements of SSPL is that anyone who implements the software and sells their implementation as a service needs to publish their source code under the SSPL license – not just changes made to the original program but all other software a user would require to run the software-as-a-service environment for themselves. Amazon used ElasticSearch for their Amazon Elasticsearch Service offering, but was unable/unwilling to continue doing so under the new license terms. In April of 2021, Amazon Web Services created a fork of ElasticSearch as the basis for OpenSearch.
Differences Between OpenSearch and ElasticSearch
After the OpenSearch fork was created, the product roadmap for ElasticSearch was driven by ElasticCo and the roadmap for OpenSearch was community driven (with significant oversight and input from Amazon) – this means the products are not identical although they provide the same core functionality. Elastic publishes a list of features unique to ElasticSearch, and the underlying machine learning algorithms are different. However, the important components of the “unique” feature list have been implemented in OpenSearch over time.
The biggest differences are price and support. OpenSearch is free software – there is no purchasing a license to unlock features. It does appear that Amazon has an internal iteration of OpenSearch as their as-a-service offering provides features not available in the open-source OpenSearch code base, but that is only available for cloud customers. ElasticCo offers ElasticSearch as free software with a limited feature set. One critical limitation is user authentication mechanisms – we are unable to implement PingID as an authentication source with the free feature set. Advanced features not currently used today – machine learning based anomaly detection, as an example – are also unavailable in the free iteration of ElasticSearch. With an ElasticSearch license, we would also get vendor support. OpenSearch does not offer vendor support, although there are third party companies that will provide support services.
Both OpenSearch and ElasticSearch have community-based support forums available – I have gotten responses from developers on both forums for questions regarding usage nuances.
Salient Feature Comparison
Most companies have a list differentiating their product from the products offered by competitors – but the important thing is how the products differ as it relates to how an individual customer uses the product. A car that can have a fresh cup of espresso waiting for you as you leave for work might be amazing to some people, but those who don’t drink coffee won’t be nearly as impressed. So how do the two products compare for me?
Data ingestion – Data is ingested using the same mechanisms – ElasticCo’s filebeat and logstash are important components of data ingestion, and these components remain unchanged. This means existing processes that feed data into ElasticSearch today would not need to be changed to begin ingesting data into OpenSearch.
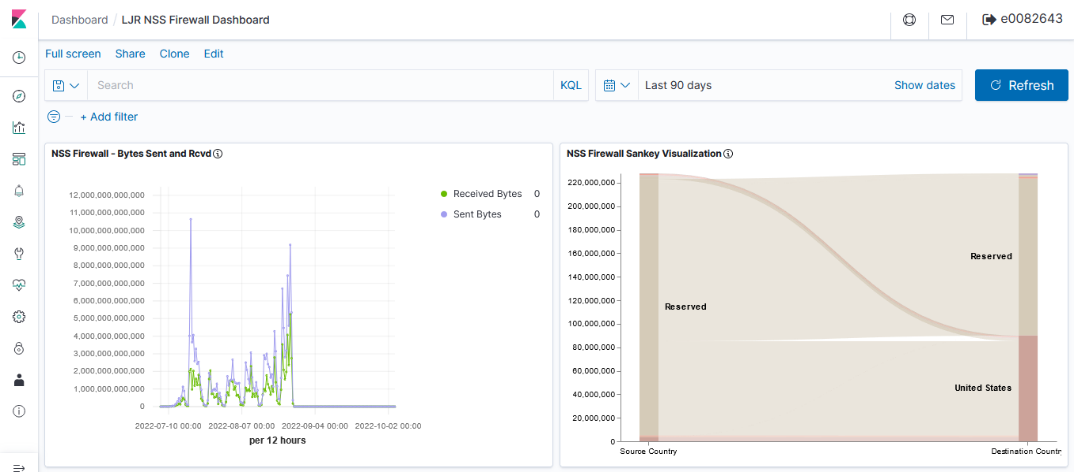
Data storage – Both products distribute searchable data over a cluster of servers. Data storage is “tiered” as hot, warm, and cold which allows less used data to reside on slower, less expensive resources. We have confirmed that ingested data is properly housed on cluster nodes designated for ‘hot’ storage and moved to ‘warm’ and ‘cold’ storage as dictated by defined policies. The item count to size ratio is similar between both products (i.e. storing ten million documents takes about the same amount of disk space). OpenSearch provides the ability to alert on transition failures (moving from hot to warm, for instance) which will reduce the amount of manual “health checking” required for the environment.
Search and aggregation – Both products allow both GUI and API searches of indexed data. Data can be aggregated as it is searched – returning the max/min/average value from a search, a count of records matching search criterion, creating sub-aggregations. ElasticSearch does have aggregations not available in OpenSearch, although these could be handled through custom scripted aggregations and many have corresponding GitHub issues requesting such an aggregation be added to OpenSearch (e.g. weighted average, geohash grid, or geotile grid)
Aggregation Name
ElasticSearch 8.x
OpenSearch 2.x
auto-interval date histogram
x
categorize text
x
children
x
composite
x
frequent items
x
geohex grid
x
geotile grid
x
ip prefix
x
multi terms
x
parent
x
random sampler
x
rare terms
x
terms
x
variable width histogram
x
boxplot
x
geo-centroid
x
geo-line
x
median absolute deviation
x
rate
x
string stats
x
t-test
x
top metrics
x
weighted avg
x
Alerting – ElastAlert2 can be used to provide the same index monitoring and alerting functionality that ElastAlert currently provides with ElasticSearch. Additionally, OpenSearch includes a built-in alerting capability that might allow us to streamline the functionality into the base OpenSearch implementation.
API Access – Both ElasticSearch and OpenSearch provide API-based access to data. Queries to the ElasticSearch API endpoint returned expected data when directed to the OpenSearch API endpoint. The ElasticSearch python module can be used to access OpenSearch data, although there is a specific OpenSearch module as well.
UX – ElasticSearch allows users to search and visualize data through Kibana; OpenSearch provides graphical user access in OpenSearch Dashboard. While the “look and feel” of the GUI differs (Kibana 8 looks different than the Kibana 7 we use today, too), the user functionality remains the same.
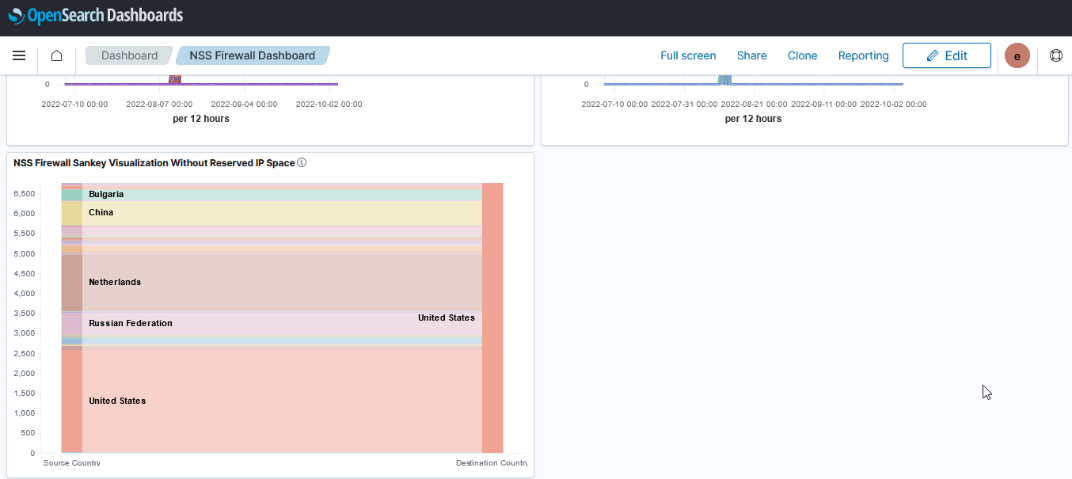
Currently used visualizations are available in both Kibana and OpenSearch Dashboards
Kibana Visualization
OpenSearch Dashboards Visualization
But there are some currently unused visualizations that are unique to each product.
Visualization
Kibana
OpenSearch Dashboard
Area
x
x
Controls
x
x
Coordinate Map
x
Data Table
x
x
Gantt Chart
x
Gauge
x
x
Goal
x
x
Heat Map
x
x
Horizonal Bar
x
x
Lens
x
Line
x
x
Maps
x
Markdown
x
x
Metric
x
x
Pie
x
x
Region Map
x
Tag Cloud
x
x
Timeline
x
x
TSVB
x
x
Vega
x
x
Vertical Bar
x
x
Dashboards can be used to group visualizations.
Kibana
OpenSearch Dashboards
New features will be available in either OpenSearch or a licensed installation of ElasticSearch. Currently data is either retained as written or aged out of the system to save disk space. Either path allows us to roll up data – as an example retaining the total number of users per month or total bytes per month instead of retaining each detailed record. Additionally, we will be able to use the “anomaly detection” which is able to monitor large volumes of index data and highlight unusual events. Both newer ElasticSearch versions and OpenSearch offer a Tableau connector which may make data stored in the platform more accessible to users.
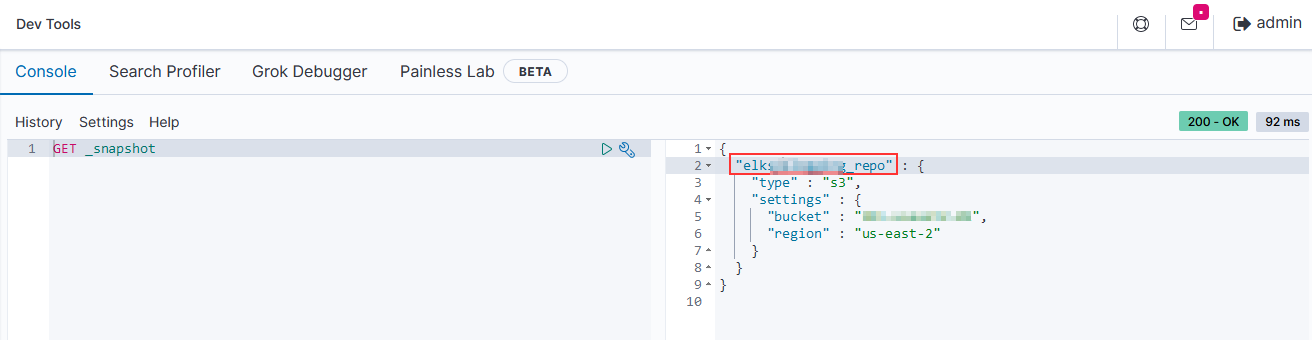
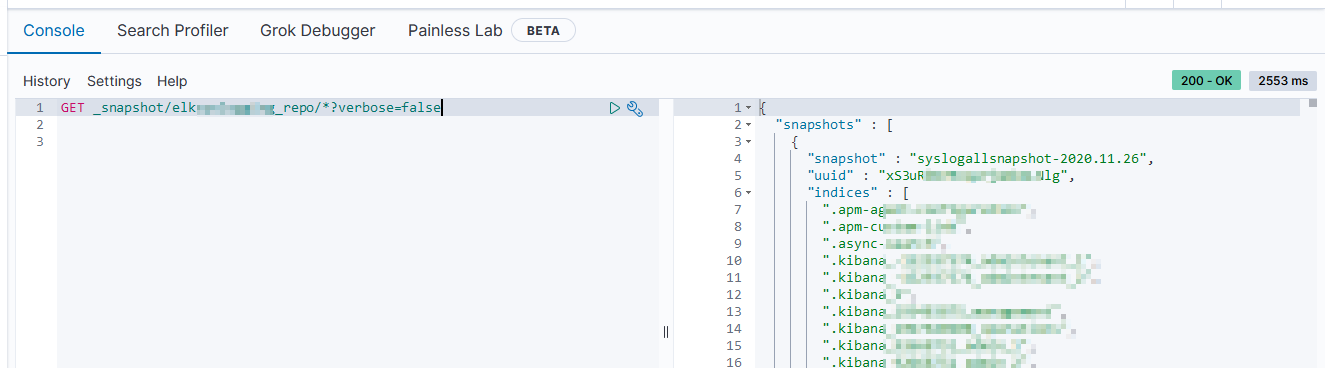
To view the snapshots held in AWS, you should be able to use Kibana. From “Management” navigate to “Snapshot and Restore” and look at the list of snapshots. We, however, get a timeout attempting to view the snapshots. Instead, use the _snapshot ES API endpoint to get the name of the repository:
Then use the name to create the ES API URI to get a list of snapshots in the repository – GET _snapshot/*?verbose=false – you will get a list of snapshots, which indices are included in each snapshot, and a state (SUCCESS or FAILED).
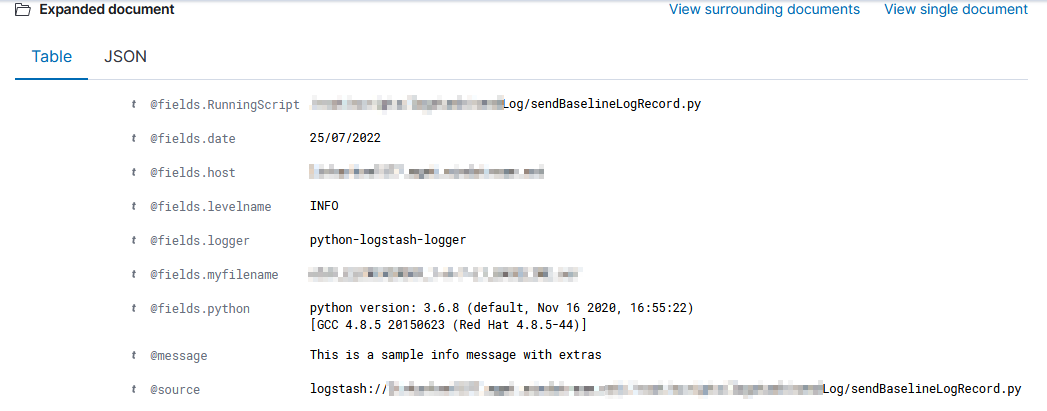
I’ve been working on forking log data into two different indices based on an element contained within the record — if the filename being sent includes the string “BASELINE”, then the data goes into the baseline index, otherwise it goes into the scan index. The data being ingested has the file name in “@fields.myfilename”
It took a while to figure out how to get the value from the current data — event.get(‘[@fields][myfilename]’) to get the @fields.myfilename value.
The following logstash config accepts JSON inputs, parses the underscore-delimited filename into fields, replaces the dashes with underscores as KDL doesn’t handle dashes and wildcards in searches, and adds a flag to any record that should be a baseline. In the output section, that flag is then used to publish data to the appropriate index based on the baseline flag value.
There’s often a difference between hypothetical (e.g. the physics formula answer) and real results — sometimes this is because sciences will ignore “negligible” factors that can be, well, more than negligible, sometimes this is because the “real world” isn’t perfect. In transmission media, this difference is a measurable “loss” — hypothetically, we know we could send X data in Y delta-time, but we only sent X’. Loss also happens because stuff breaks — metal corrodes, critters nest in fiber junction boxes, dirt builds up on a dish. And it’s not easy, when looking at loss data at a single point in time, to identify what’s normal loss and what’s a problem.
We’re starting a project to record a baseline of loss for all sorts of things — this will allow individuals to check the current loss data against that which engineers say “this is as good as it’s gonna get”. If the current value is close … there’s not a problem. If there’s a big difference … someone needs to go fix something.
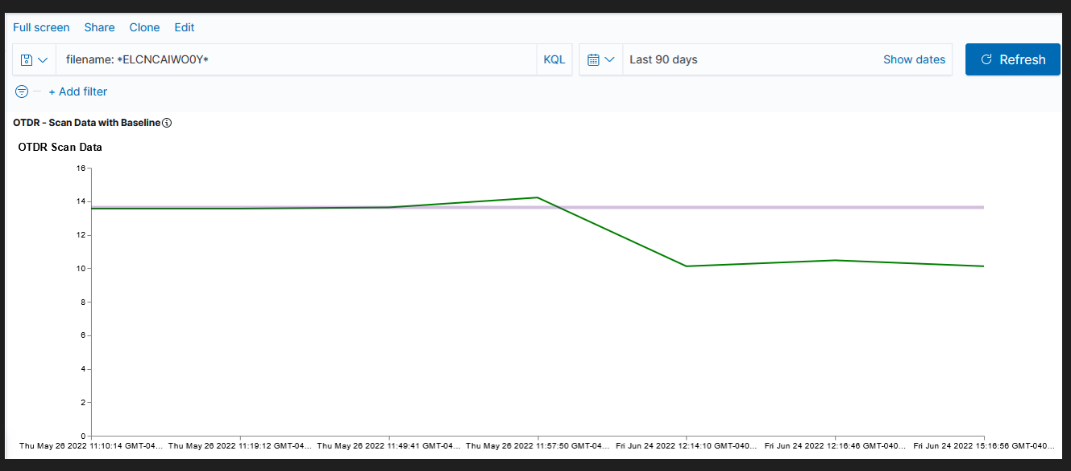
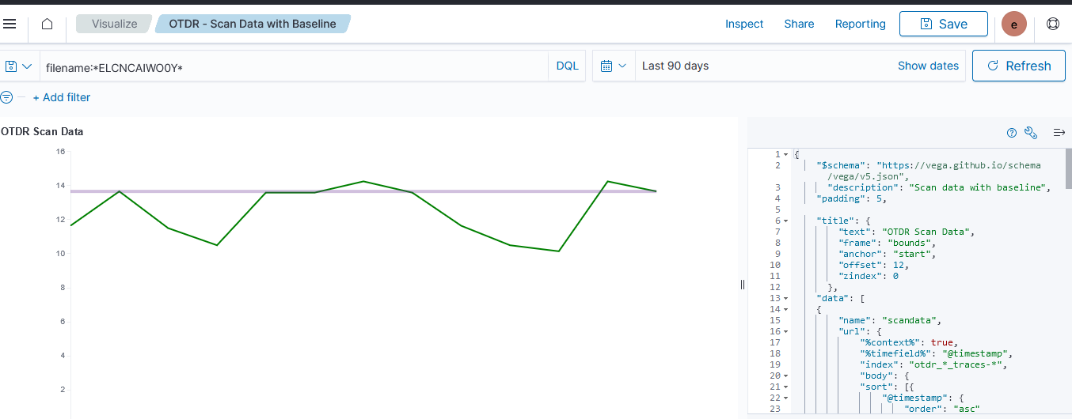
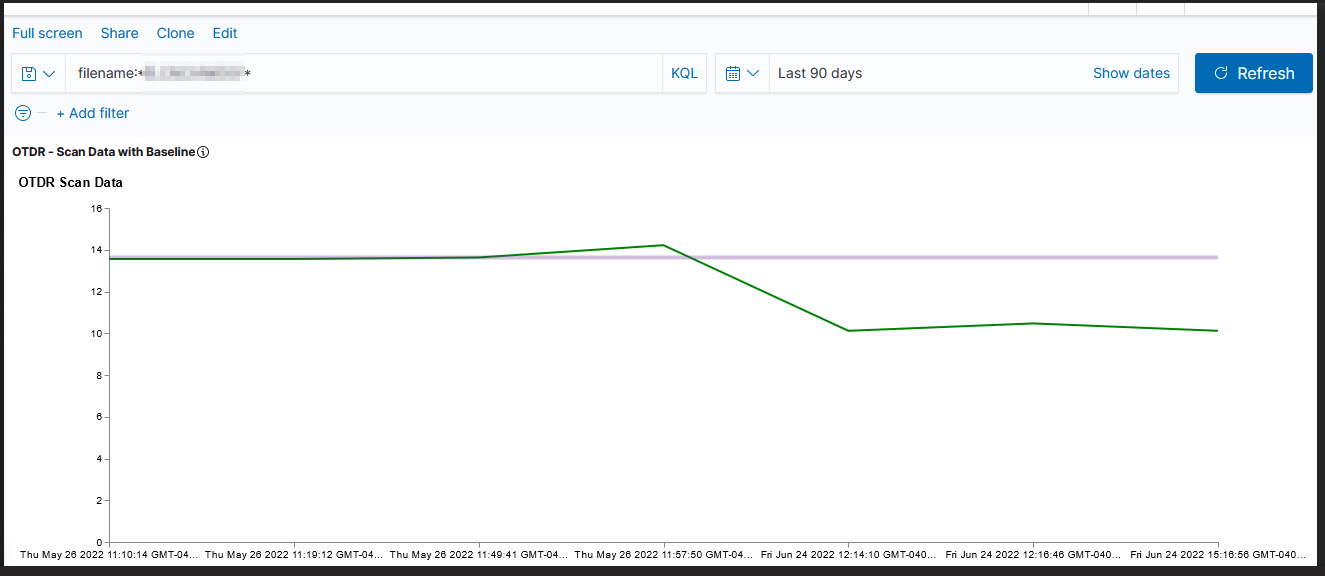
Unfortunately, creating a graph in Kibana that shows the baseline was … not trivial. There is a rule mark that allows you to draw a straight line between two points. You cannot just say “draw a line at y from 0 to some large value that’s going to be off the graph. The line doesn’t render (say, 0 => today or the year 2525). You cannot just get the max value of the axis.
I finally stumbled across a series of data contortions that make the baseline graphable.
The data sets I have available have a datetime object (when we measured this loss) and a loss value. For scans, there may be lots of scans for a single device. For baselines, there will only be one record.
The joinaggregate transformation method — which appends the value to each element of the data set — was essential because I needed to know the largest datetime value that would appear in the chart.
The lookup transformation method — which can access elements from other data sets — allowed me to get that maximum timestamp value into the baseline data set. Except … lookup needs an exact match in the search field. Luckily, it does return a random (I presume either first or last … but it didn’t matter in this case because all records have the same max date value) record when multiple matches are found.
Voila — a chart with a horizontal line at the baseline loss value. Yes, I randomly copied a record to use as the baseline and selected the wrong one (why some scans are below the “good as it’s ever going to get” baseline value!). But … once we have live data coming into the system, we’ll have reasonable looking graphs.
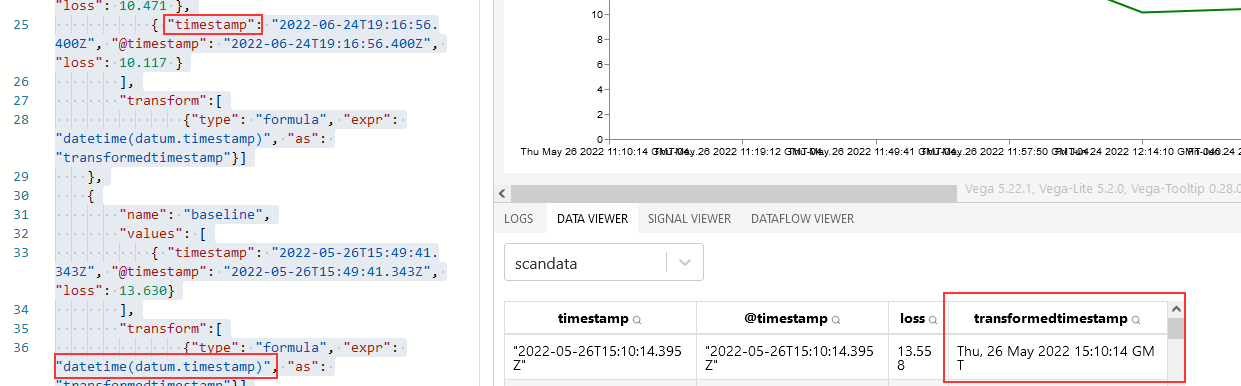
We have data created by an external source (i.e. I cannot just change the names used so it works) — the datetime field is named @timestamp and I had an awful time figuring out out how to address that element within a transformation expression.
Just to make sure I wasn’t doing something silly, I created a copy of the data element named without the at symbol. Voila – transformedtimestamp is populated with a datetime element.
I finally figured it out – it appears that I have encountered a JavaScript limitation. Instead of using the dot-notation to access the element, the array subscript method works – not datum.@timestamp in any iteration or with any combination of escapes.