In all of these examples, the copy/paste text uses localhost and port 9200. Since some of my sandboxes don’t use the default port, some of the example outputs will use a different port. Obviously, use your hostname and port. And, if your ES instance requires authentication, add the “-u” option with the user (or user:password … but that’s not a good idea outside of sandboxes as the password is then stored to the shell history). If you are using https for the API endpoint, you may also need to add the “-k” option to establish an untrusted SSL connection (e.g. the CA isn’t trusted by your OS).
curl -k -u elastic https://localhost...
Listing All Indices
Use the following command to list all of the indices in the ES system:
curl http://localhost:9200/_cat/indices?v
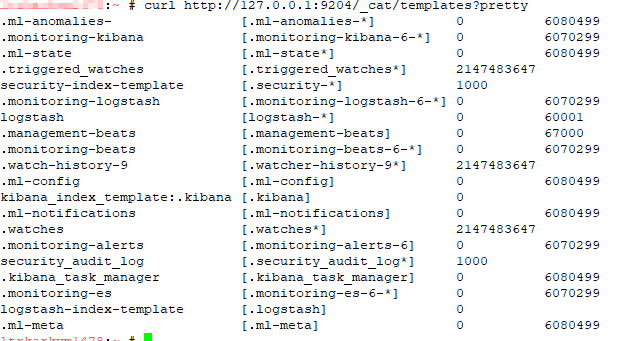
Listing All Templates
Use the following command to list all of the templates:
curl http://localhost:9200/_cat/templates?pretty
Explain Shard Allocation
I was asked to help get a ELK installation back into working order — one of the things I noticed is that all of the indices were yellow. The log file showed allocation errors. This command reported on the allocation decision that was being made. In the case I was looking at, the problem became immediately obvious — it was a single node system and 1 replica was defined. The explanation was that the shard could not be stored because it already existed in that place.
curl http://localhost:9200/_cluster/allocation/explain
If the maximum number of allocation retries has been exceeded, you can force ES to re-try allocation (as an example, a disk was full for an extended period of time but space has been cleared and everything should work now)
curl http://localhost:9200/_cluster/reroute?retry_failed=true
Set the Number of Replicas for a Single Index
Once I identified that the single node ELK instance had indices configured
curl -X PUT \
http://127.0.0.1:9200/logstash-2021.05.08/_settings \
-H 'cache-control: no-cache' \
-H 'content-type: application/json' \
-d '{"index" : {"number_of_replicas" : 0}}
'
Add an Alias to an Index
To add an alias to an existing index, use PUT /<indexname>/_alias/<aliasname> — e.g.
PUT /ljr-2022.07.05/_alias/ljr