We’ve got tassels all over now — silks on corn, cobs forming. This is the Damaun SH2 sweet corn we’ve planted for the first time this year.

We’ve got tassels all over now — silks on corn, cobs forming. This is the Damaun SH2 sweet corn we’ve planted for the first time this year.
The pumpkins are starting to look like … pumpkins!

The corn is starting to form tassels!


We have observable little proto-hazelnuts forming!

We started our three sisters planting today — about 660 sq ft of tilled soil. I found an open pollinated SH2 corn developed by Kultursaatin in Germany, which we planted today. Anya interspersed the field with Rouge Vif D’Etampes pumpkins. In about two weeks, we’ll add scarlet runner beans. Even if we don’t produce enough to sell this year, we’ll grow enough seeds to expand the garden area this year.

The whole farm area was an overgrown field, and we’ve cleared a lot of multiflora rose and brambles. But I think we’re going to let the staghorn forest stay … it’s kind of cool looking.

We’ve cleared a path to get into the farm, and Scott has been flailing the pasture. We’ve got some great trees scattered throughout the pasture — old apples, cherries, and black walnuts.

On the farm

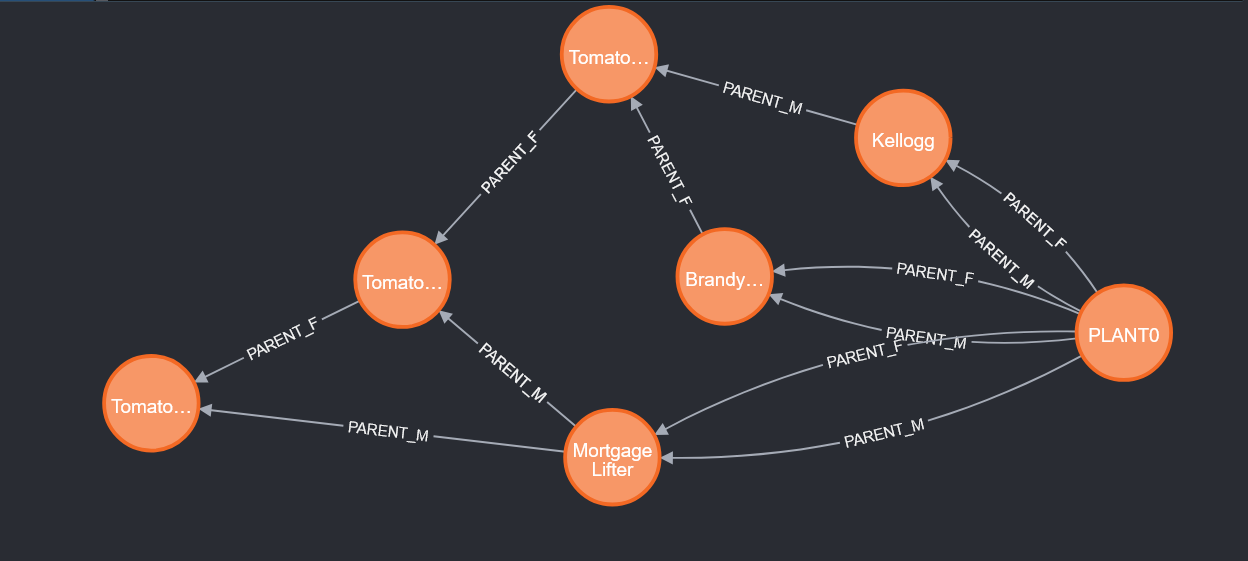
Graph databases are designed to both store data and record relationships between data elements. I wondered if this would be useful in tracking cross-breeding projects – essentially building “family trees” of the entity being cross-bred. The data model would have nodes with the hybrid with notes on it. Relationships for PARENT_M and PARENT_F (male and female parent of the hybrid) would be used to associate nodes.
Graph databases have a concept of pathing – what nodes do we need to traverse to get from A to B – but to create a lineage for the plants, you need to know the starting point. Which is great if you want to play six degrees of separation and find a path between two known people, but not great if I just want to know what the lineage is of Tomato #198. To make pathing possible, I needed to add a common root node to all of heirloom seedstocks – PLANT0
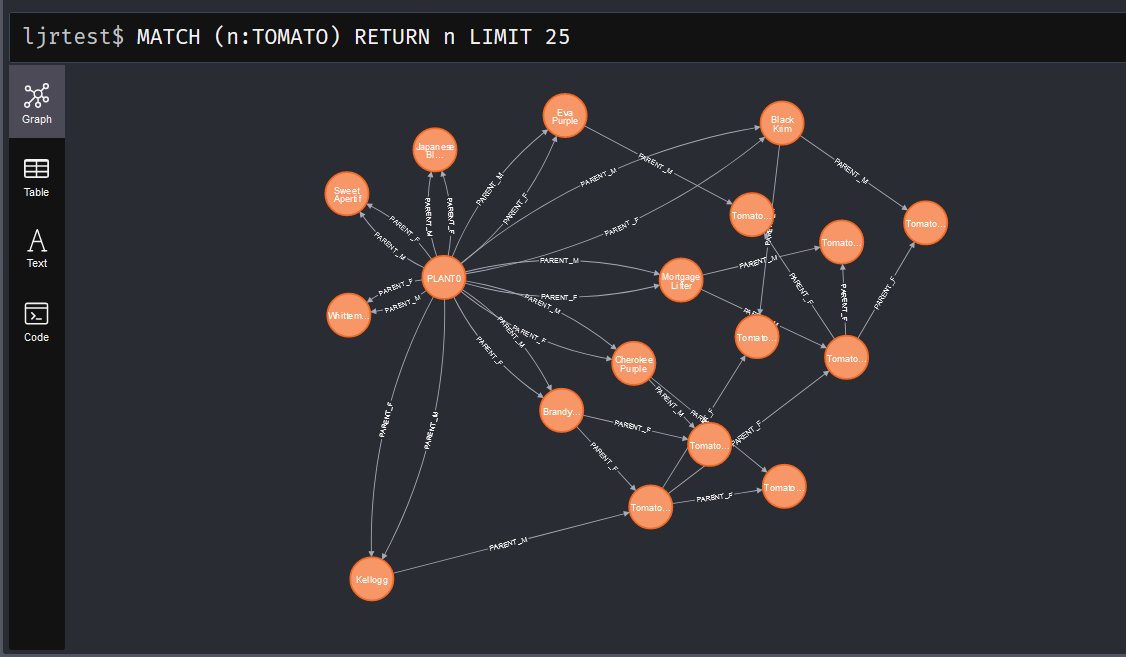
This allows me to take any plant and find the paths from PLANT0 to it
MATCH
p=(Tomato0:TOMATO {name: 'PLANT0'})-[*]->(Tomato8:TOMATO{name: 'Tomato0000008'})
RETURN p
And visualize the genetic heritage of the hybrid.