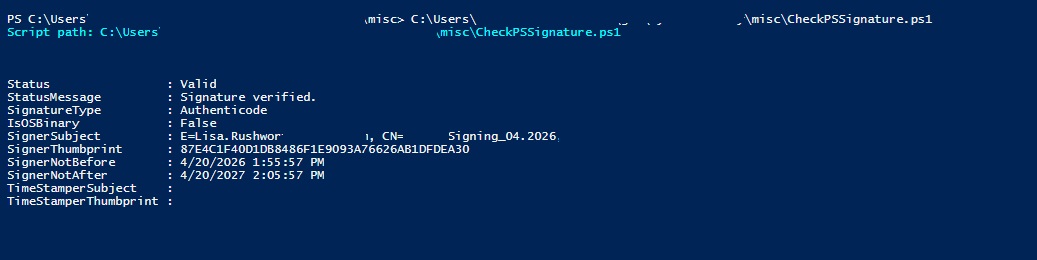
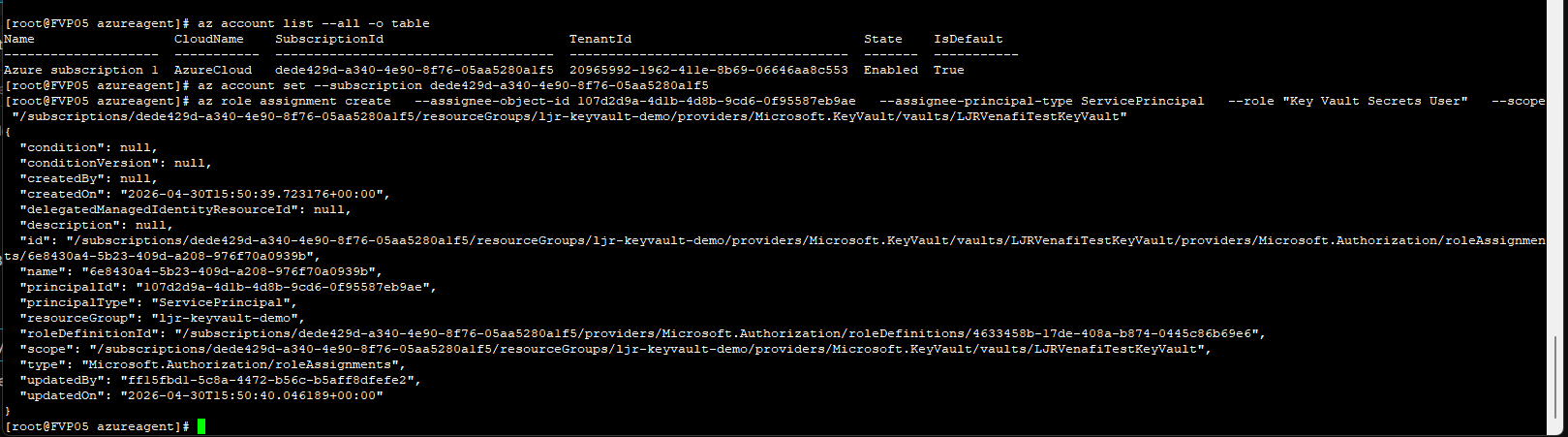
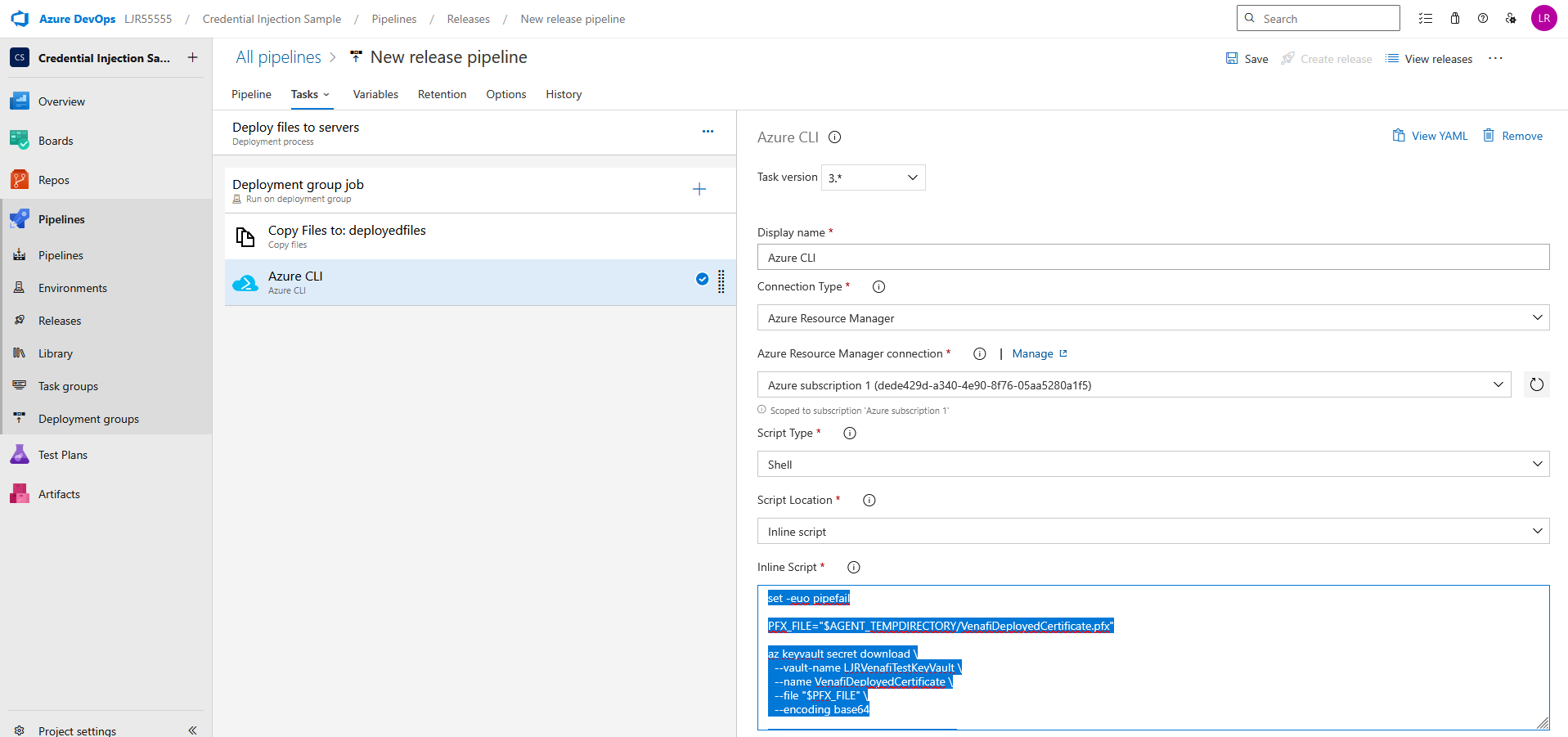
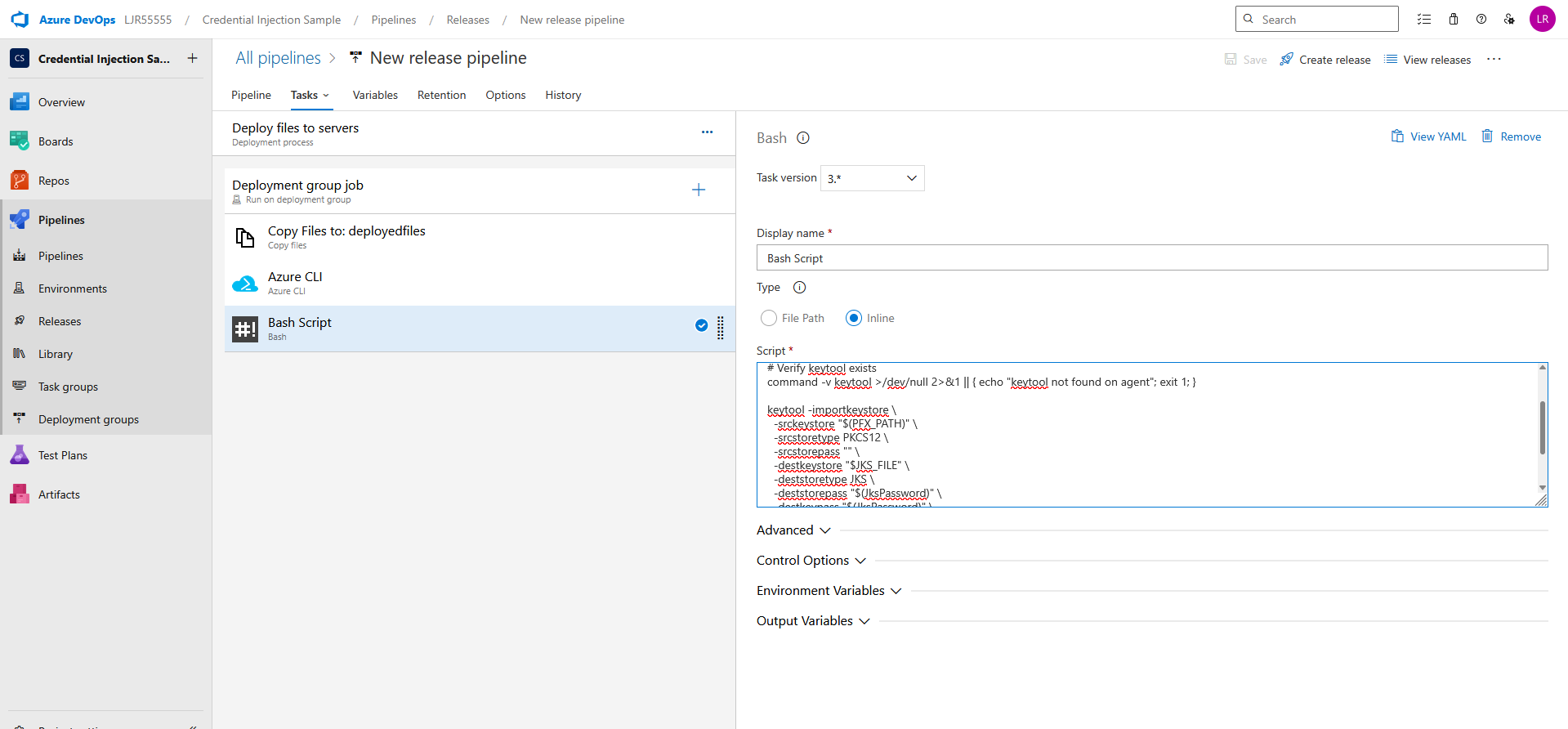
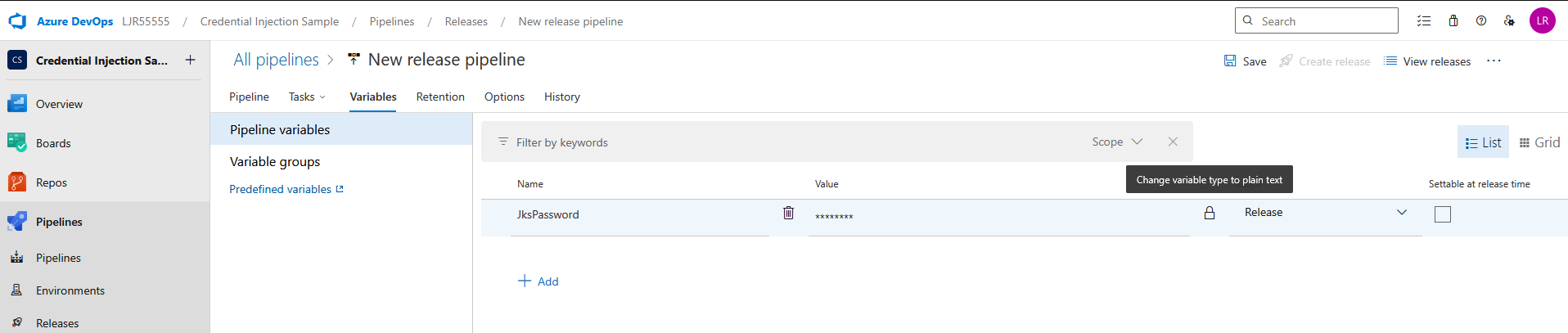
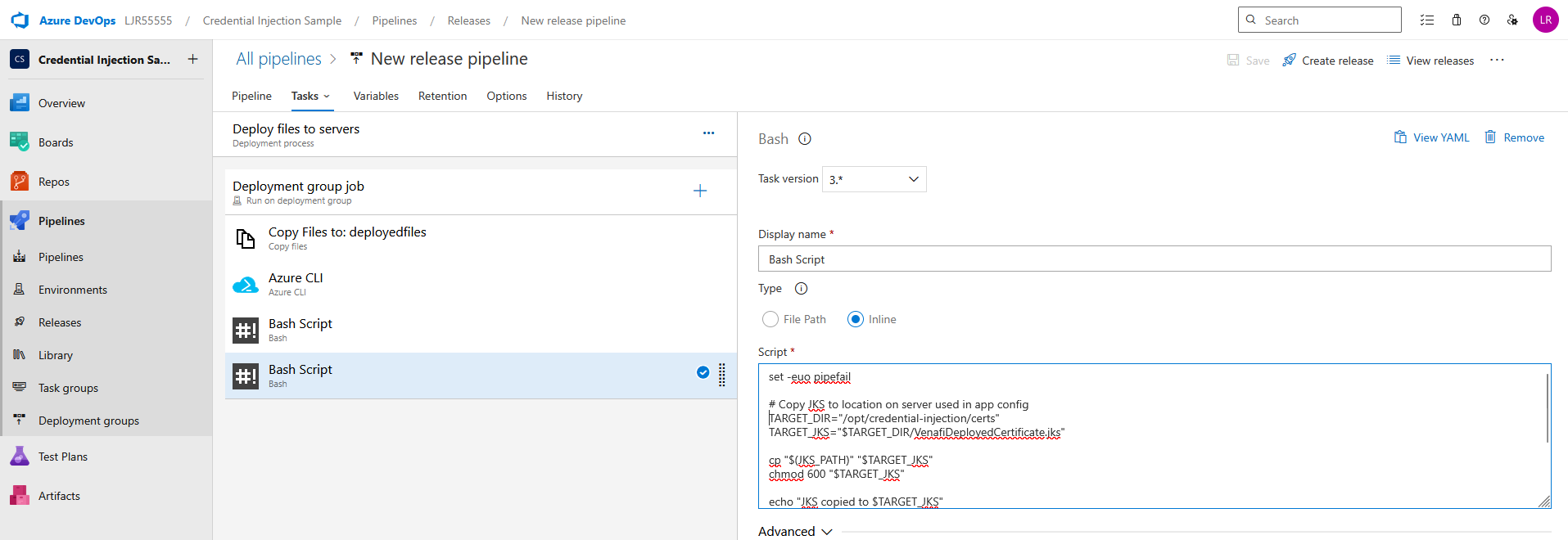
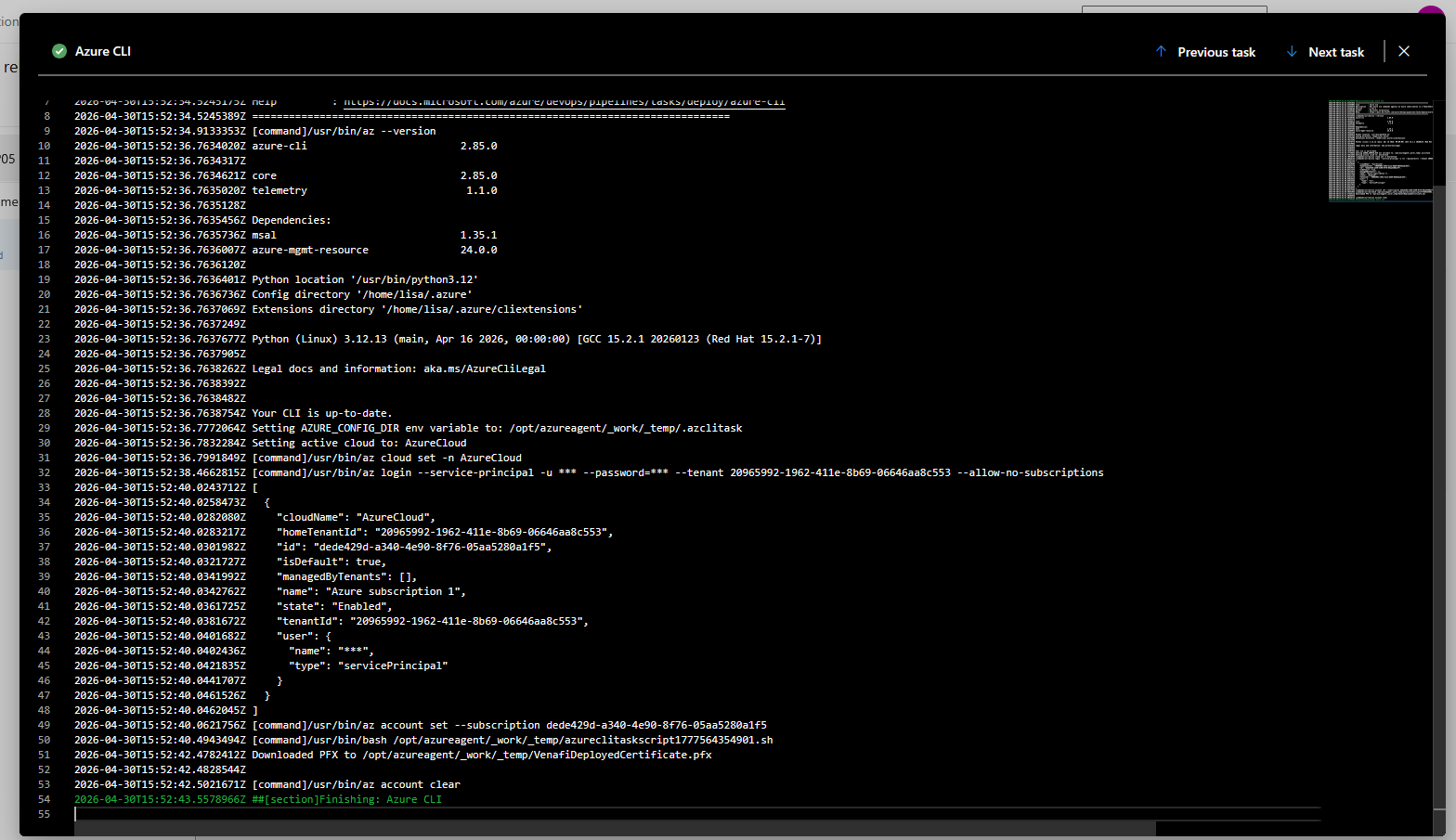
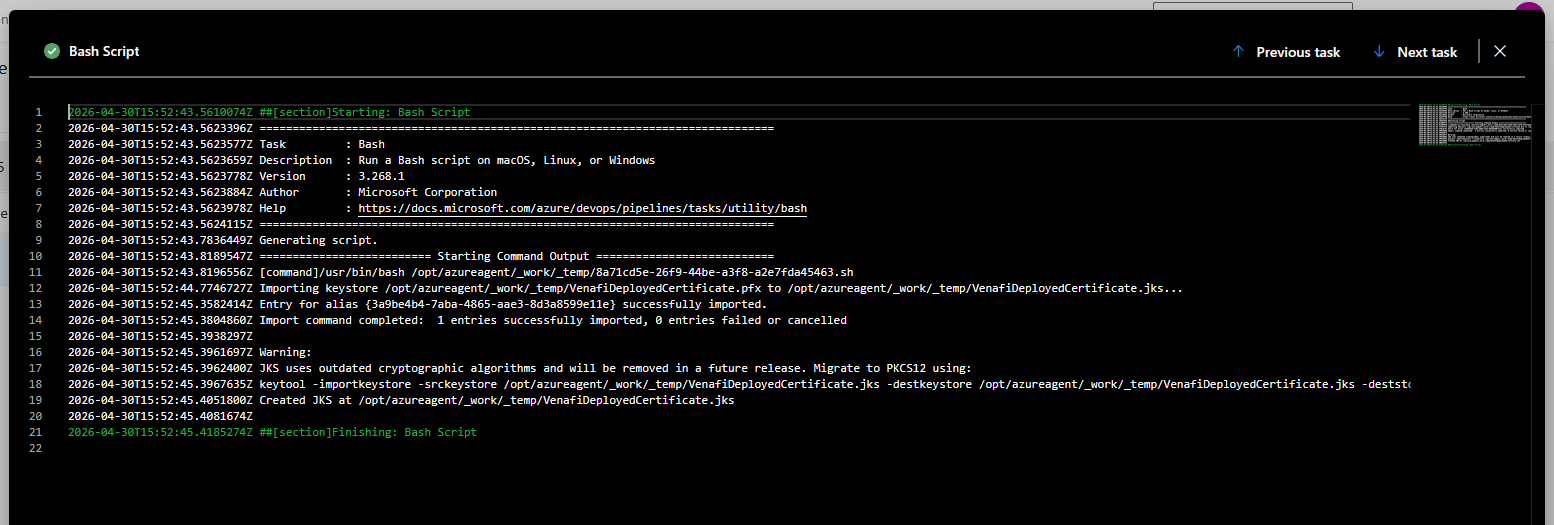
Powershell script that verifies WinRM access and lists certs from CAPI store.
# ============================================================================
# User-configurable variables
# ============================================================================
$TargetHost = ‘hostname.example.com’
$TargetLocalComputerName = ‘HOSTNAME
$Username = ‘localuserid’
$Password = ‘localuserpassword’
$Port = 5985
Set-StrictMode -Version Latest
$ErrorActionPreference = ‘Stop’
# Remote certificate store to inspect.
# Common values:
# Cert:\LocalMachine\My
# Cert:\LocalMachine\WebHosting
# Cert:\LocalMachine\Root
# Cert:\LocalMachine\CA
$RemoteCertStorePath = ‘Cert:\LocalMachine\My’
# Optional subject filter. Leave blank to return everything in the store.
$CertificateSubjectFilter = ”
# ============================================================================
# Build local SAM credential
# ============================================================================
# Unqualified – fails
# $QualifiedUsername = $Username
# .\ – works
# $QualifiedUsername = ‘{0}\{1}’ -f ‘.’, $Username
# With hostname – works
$QualifiedUsername = ‘{0}\{1}’ -f $TargetLocalComputerName, $Username
$SecurePassword = ConvertTo-SecureString -String $Password -AsPlainText -Force
$Credential = [System.Management.Automation.PSCredential]::new($QualifiedUsername, $SecurePassword)
# ============================================================================
# Check TrustedHosts on the client
# ============================================================================
$trustedHostsValue = (Get-Item WSMan:\localhost\Client\TrustedHosts).Value
$trustedHostEntries = @()
if (-not [string]::IsNullOrWhiteSpace($trustedHostsValue)) {
$trustedHostEntries = $trustedHostsValue -split ‘\s*,\s*’ | Where-Object {
-not [string]::IsNullOrWhiteSpace($_)
}
}
$trustedHostMatch = $false
foreach ($entry in $trustedHostEntries) {
if ($TargetHost -like $entry -or $TargetLocalComputerName -like $entry) {
$trustedHostMatch = $true
break
}
}
Write-Host ”
Write-Host ‘=== Client Context ===’ -ForegroundColor Cyan
[pscustomobject]@{
RunningAs = [System.Security.Principal.WindowsIdentity]::GetCurrent().Name
TargetHost = $TargetHost
Port = $Port
CredentialUser = $Credential.UserName
TrustedHostsValue = $trustedHostsValue
TrustedHostMatched = $trustedHostMatch
RemoteCertStorePath = $RemoteCertStorePath
CertificateSubjectFilter = $CertificateSubjectFilter
} | Format-List
if (-not $trustedHostMatch) {
Write-Warning “TrustedHosts does not appear to include $TargetHost or $TargetLocalComputerName. HTTP/5985 with a local account will usually fail until that is fixed.”
}
# ============================================================================
# Raw TCP check
# ============================================================================
Write-Host ”
Write-Host ‘=== TCP Connectivity Check ===’ -ForegroundColor Cyan
$tcpClient = [System.Net.Sockets.TcpClient]::new()
try {
$asyncResult = $tcpClient.BeginConnect($TargetHost, $Port, $null, $null)
if (-not $asyncResult.AsyncWaitHandle.WaitOne(3000, $false)) {
throw “Timed out connecting to $TargetHost`:$Port”
}
$null = $tcpClient.EndConnect($asyncResult)
Write-Host “TCP connect to $TargetHost`:$Port succeeded.” -ForegroundColor Green
}
catch {
Write-Host “TCP connect to $TargetHost`:$Port failed: $($_.Exception.Message)” -ForegroundColor Red
throw
}
finally {
$tcpClient.Dispose()
}
# ============================================================================
# WinRM over HTTP/5985 test + remote machine-store certificate inventory
# ============================================================================
Write-Host ”
Write-Host ‘=== WinRM HTTP/5985 Test ===’ -ForegroundColor Cyan
$session = $null
try {
$session = New-PSSession `
-ComputerName $TargetHost `
-Port $Port `
-Authentication Negotiate `
-Credential $Credential `
-ErrorAction Stop
$remoteResult = Invoke-Command -Session $session -ErrorAction Stop -ArgumentList $RemoteCertStorePath, $CertificateSubjectFilter -ScriptBlock {
param(
[string]$StorePath,
[string]$SubjectFilter
)
$latfp = $null
try {
$latfp = Get-ItemPropertyValue `
-Path ‘HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System’ `
-Name ‘LocalAccountTokenFilterPolicy’ `
-ErrorAction Stop
}
catch {
$latfp = $null
}
$identity = [System.Security.Principal.WindowsIdentity]::GetCurrent()
$principal = [System.Security.Principal.WindowsPrincipal]::new($identity)
$isAdmin = $principal.IsInRole([System.Security.Principal.WindowsBuiltInRole]::Administrator)
if (-not (Test-Path -Path $StorePath)) {
throw “Certificate store path not found: $StorePath”
}
$certs = Get-ChildItem -Path $StorePath -ErrorAction Stop
if (-not [string]::IsNullOrWhiteSpace($SubjectFilter)) {
$certs = $certs | Where-Object { $_.Subject -like “*$SubjectFilter*” }
}
$certInventory = foreach ($cert in $certs | Sort-Object NotAfter, Subject) {
$sanEntries = @()
$dnsNameList = $null
try {
$dnsNameList = $cert.DnsNameList
}
catch {
$dnsNameList = $null
}
if ($null -ne $dnsNameList) {
foreach ($dnsName in $dnsNameList) {
if ($null -ne $dnsName -and -not [string]::IsNullOrWhiteSpace($dnsName.Unicode)) {
$sanEntries += $dnsName.Unicode
}
}
}
$ekuEntries = @()
foreach ($eku in $cert.EnhancedKeyUsageList) {
if (-not [string]::IsNullOrWhiteSpace($eku.FriendlyName)) {
$ekuEntries += $eku.FriendlyName
}
elseif (-not [string]::IsNullOrWhiteSpace($eku.ObjectId)) {
$ekuEntries += $eku.ObjectId
}
}
[pscustomobject]@{
StorePath = $StorePath
Subject = $cert.Subject
Thumbprint = $cert.Thumbprint
NotBefore = $cert.NotBefore
NotAfter = $cert.NotAfter
HasPrivateKey = $cert.HasPrivateKey
Issuer = $cert.Issuer
SerialNumber = $cert.SerialNumber
SignatureAlgorithm = $cert.SignatureAlgorithm.FriendlyName
PublicKeyOid = $cert.PublicKey.Oid.FriendlyName
Archived = $cert.Archived
DnsNames = ($sanEntries -join ‘; ‘)
EnhancedKeyUsage = ($ekuEntries -join ‘; ‘)
PSParentPath = $cert.PSParentPath
}
}
[pscustomobject]@{
RemoteComputerName = $env:COMPUTERNAME
RemoteIdentity = $identity.Name
IsAdministrator = $isAdmin
LocalAccountTokenFilterPolicy = $latfp
WinRMServiceStatus = (Get-Service -Name WinRM).Status.ToString()
PSVersion = $PSVersionTable.PSVersion.ToString()
QueriedStorePath = $StorePath
CertificateCount = @($certInventory).Count
Certificates = @($certInventory)
}
}
Write-Host ‘WinRM HTTP/5985 test succeeded.’ -ForegroundColor Green
Write-Host ”
Write-Host ‘=== Remote Probe Data ===’ -ForegroundColor Cyan
[pscustomobject]@{
RemoteComputerName = $remoteResult.RemoteComputerName
RemoteIdentity = $remoteResult.RemoteIdentity
IsAdministrator = $remoteResult.IsAdministrator
LocalAccountTokenFilterPolicy = $remoteResult.LocalAccountTokenFilterPolicy
WinRMServiceStatus = $remoteResult.WinRMServiceStatus
PSVersion = $remoteResult.PSVersion
QueriedStorePath = $remoteResult.QueriedStorePath
CertificateCount = $remoteResult.CertificateCount
} | Format-List
Write-Host ”
Write-Host “=== Certificates in $($remoteResult.QueriedStorePath) ===” -ForegroundColor Cyan
if ($remoteResult.CertificateCount -eq 0) {
Write-Host ‘No certificates matched the requested store/filter.’ -ForegroundColor Yellow
}
else {
$remoteResult.Certificates |
Select-Object Subject, Thumbprint, NotAfter, HasPrivateKey, DnsNames, EnhancedKeyUsage |
Format-Table -Wrap -AutoSize
}
Write-Host ”
Write-Host ‘=== Computed Summary ===’ -ForegroundColor Cyan
[pscustomobject]@{
Http5985Success = $true
RemoteIdentity = $remoteResult.RemoteIdentity
IsAdministrator = $remoteResult.IsAdministrator
LocalAccountTokenFilterPolicy = $remoteResult.LocalAccountTokenFilterPolicy
WinRMServiceStatus = $remoteResult.WinRMServiceStatus
QueriedStorePath = $remoteResult.QueriedStorePath
CertificateCount = $remoteResult.CertificateCount
} | Format-List
}
catch {
Write-Host “WinRM HTTP/5985 test failed: $($_.Exception.Message)” -ForegroundColor Red
[pscustomobject]@{
Http5985Success = $false
ErrorMessage = $_.Exception.Message
HResult = (‘0x{0:X8}’ -f ($_.Exception.HResult -band 0xffffffff))
FullyQualifiedErrorId = $_.FullyQualifiedErrorId
} | Format-List
}
finally {
if ($null -ne $session) {
Remove-PSSession -Session $session -ErrorAction SilentlyContinue
}
}