The application I am registering will pull report data from Graph for use within existing company systems. I will be assigning application-level permissions and no callback URL is needed.
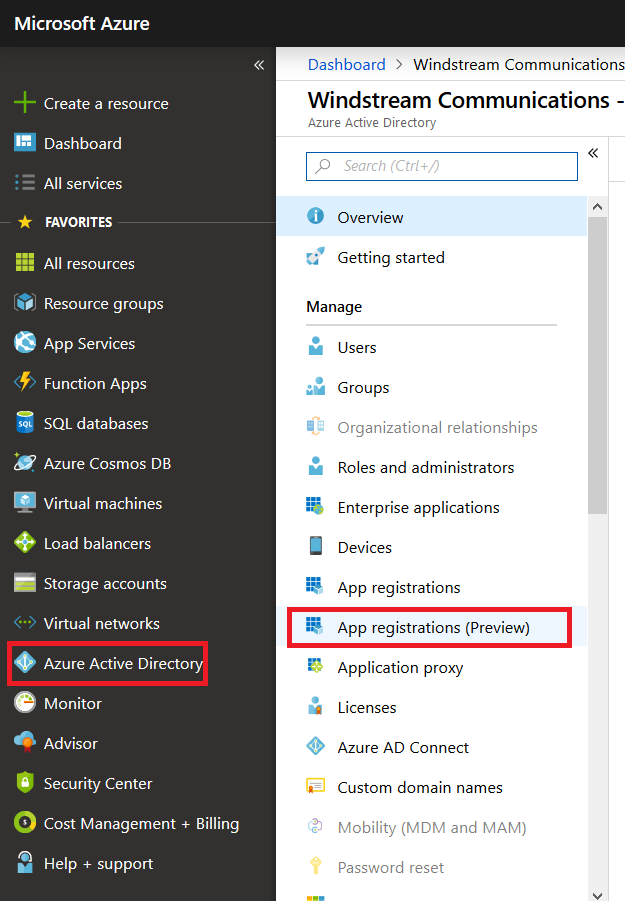
To register an application, log into http://portal.azure.com and select “Azure Active Directory” from the left-hand navigation column. Then select “App Registrations (preview)”.
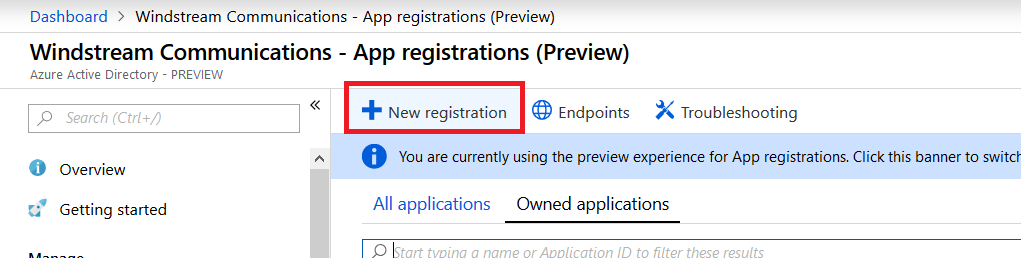
Click on “New registration”
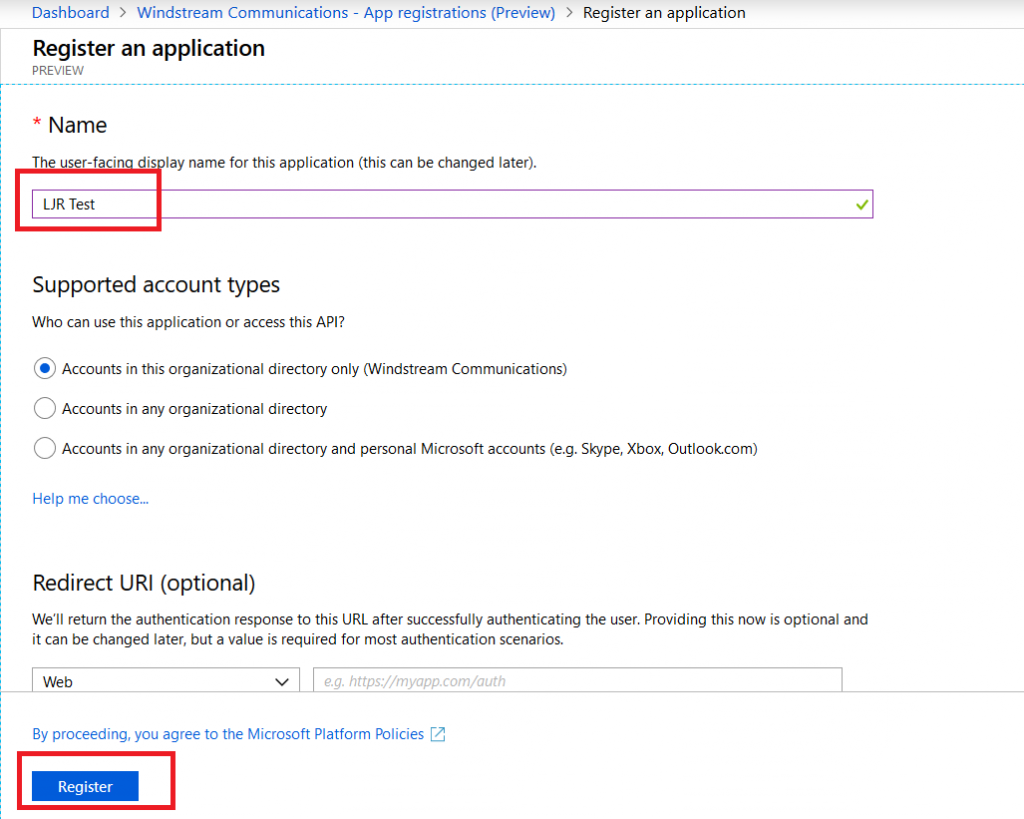
Provide a descriptive name for the application — tenant managers can see all of the registered applications and it’s a lot easier if you ask them to approve access for “Specific Application Name For Engineering” than “LJR Test”.
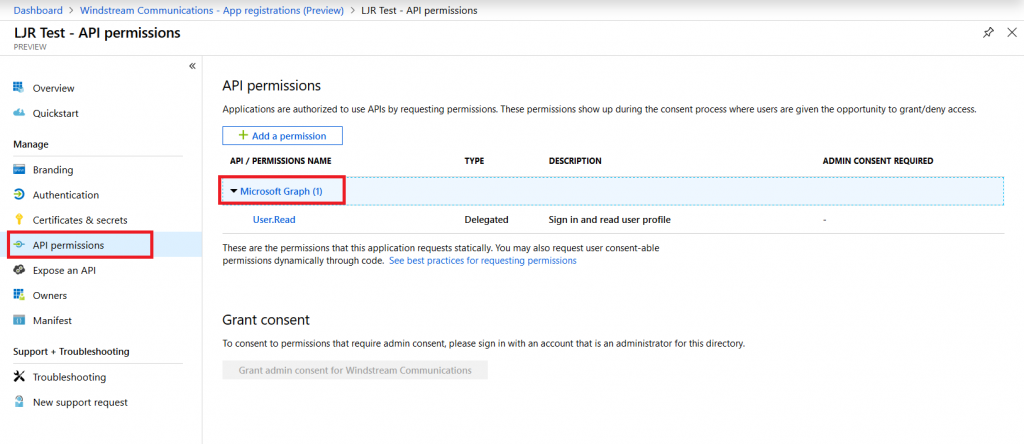
The application will be created and you will be brought to the app overview. Select “API permissions” then click the “Microsoft Graph” hyperlink.
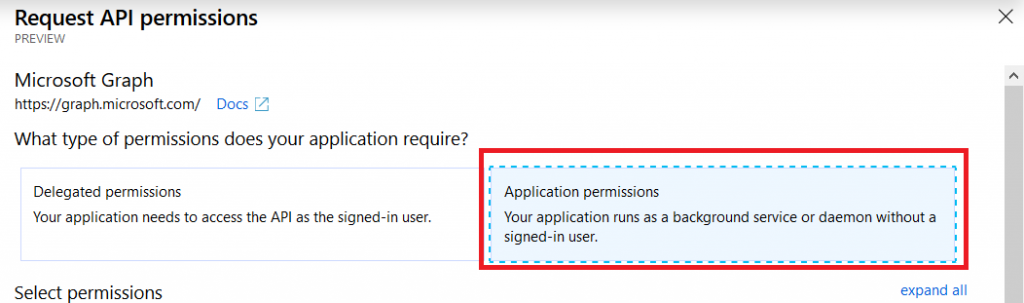
Click on “Application permissions”
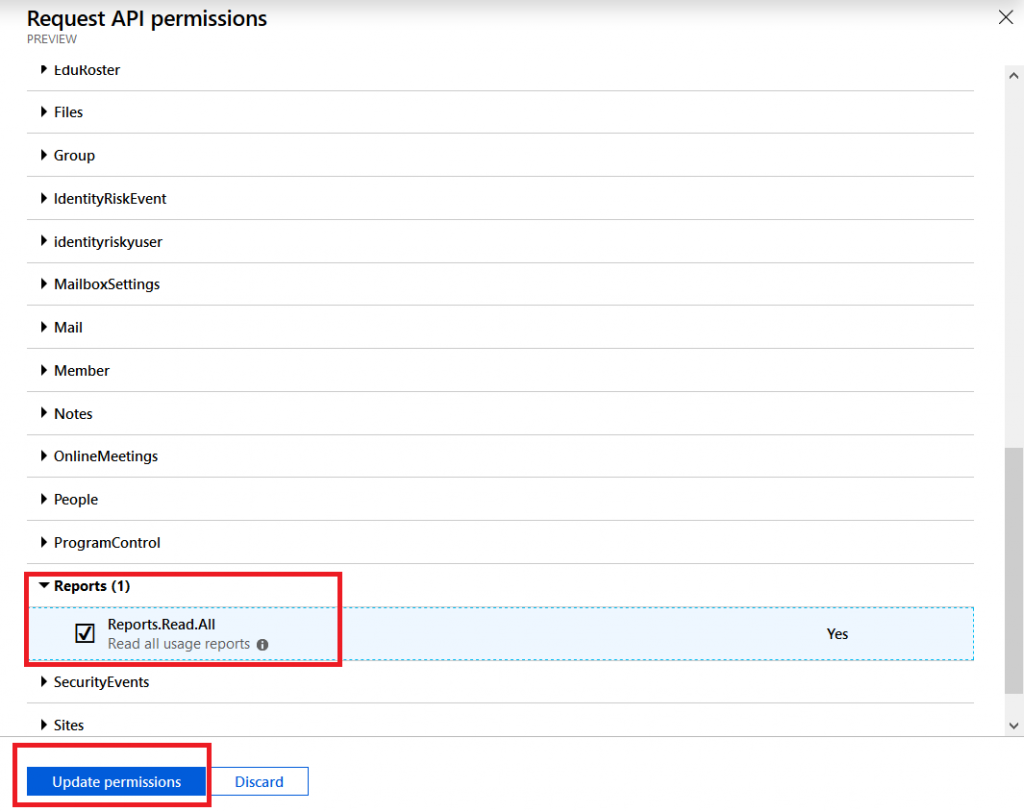
And find the permissions you need. For the script I want to run, I need Reports.Read.All. Click “Update permissions” to save your changes.
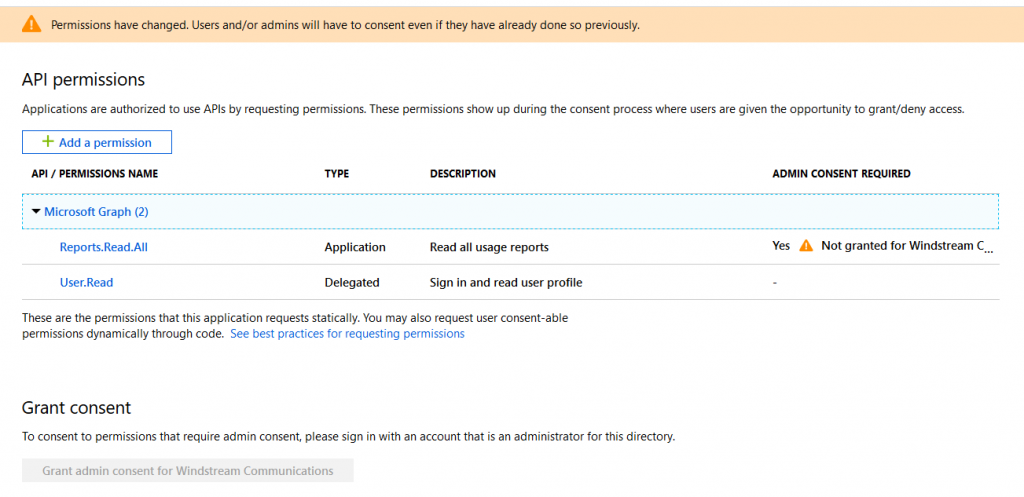
If you are a tenant admin, you can approve your own rights. Otherwise, you’ll need to contact a tenant admin and have them approve the permissions you have requested. Once the permissions have been acknowledged, you’re ready to go.
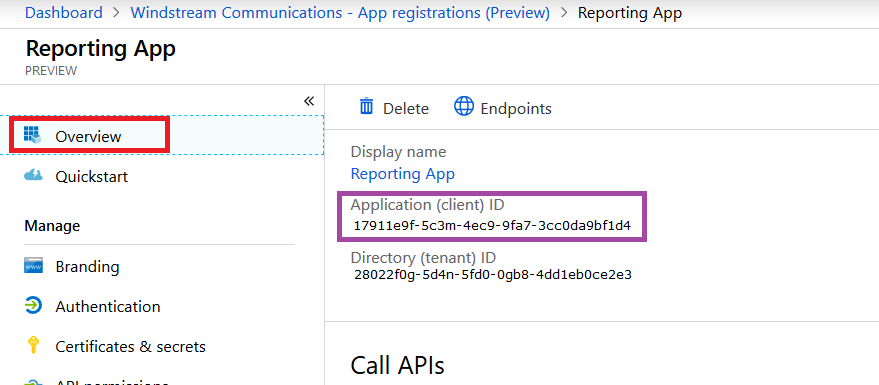
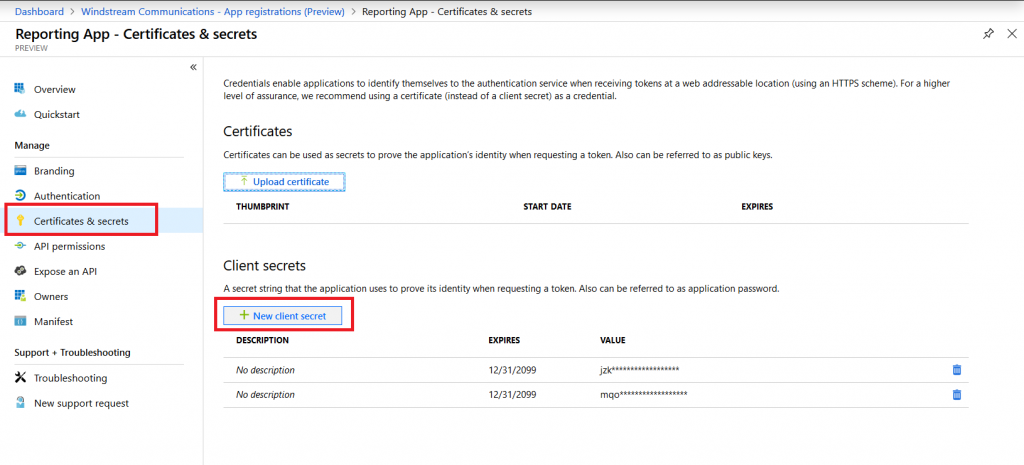
You will need the app ID and a secret for use within your code. The application ID is listed on the application “Overview”.
To create a secret, select “Certificates & secrets” then click “New client secret”. This is displayed one time, so copy it into your code now.
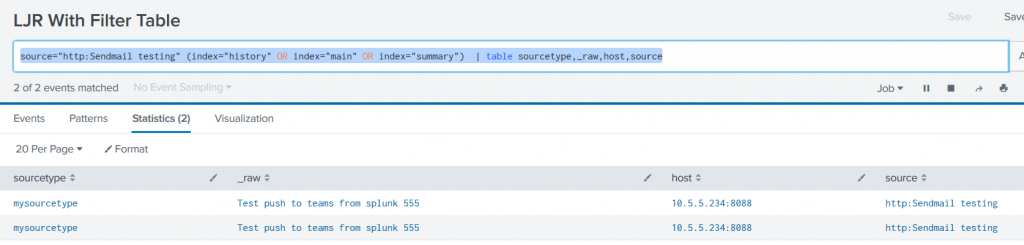
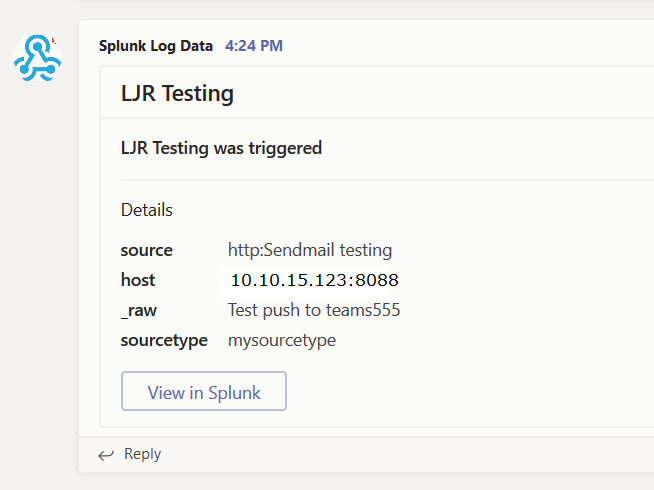
We managed to use the stock Teams webhook app in Splunk — just needed to modify the search being used. Adding “|table” and specific fields to be included in the table avoids having to filter the list data within the Python code
There still is a tweak to the code that I prefer — Python lists aren’t in any particular order. I’d like to be able to look the same place in the Teams post to see a particular field. Adding a sort when the facts array is put into the post body ensures the fields are in the same order each time.
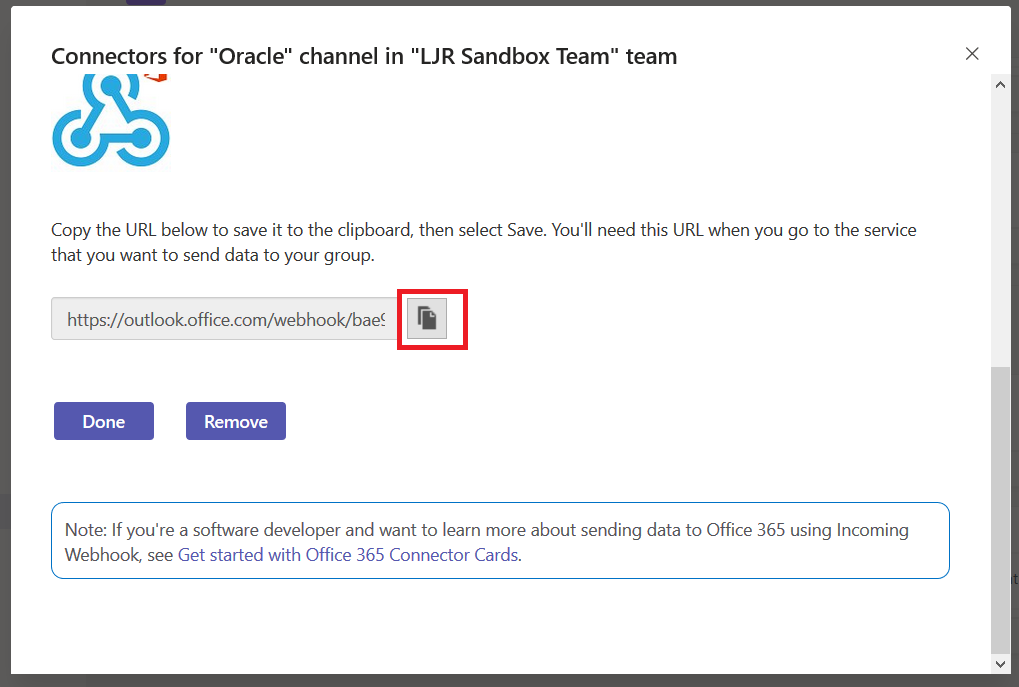
Using either the default webhook action or the Teams-specific webhook, Splunk searches can post data into Microsoft Teams. First, you need to get a webhook URL for your Teams channel. On the hamburger menu next to the channel, select “Connectors”. Select Webhook, provide a name for the webhook, and copy the webhook URL.
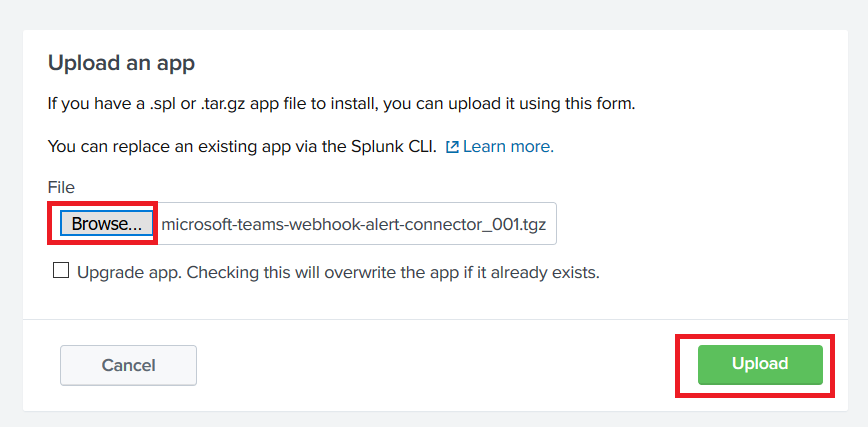
If you intend to use the generic webhook app, there is no need to install the Teams-specific one. The Teams-specific app gives you prettier output & a “view in splunk” button. Download the app tgz. To install the app, go into “Manage Apps” and select “Install app from file”.
Click ‘Browse…’ and find the tgz you downloaded. Click ‘Upload’ to install the app to Splunk.
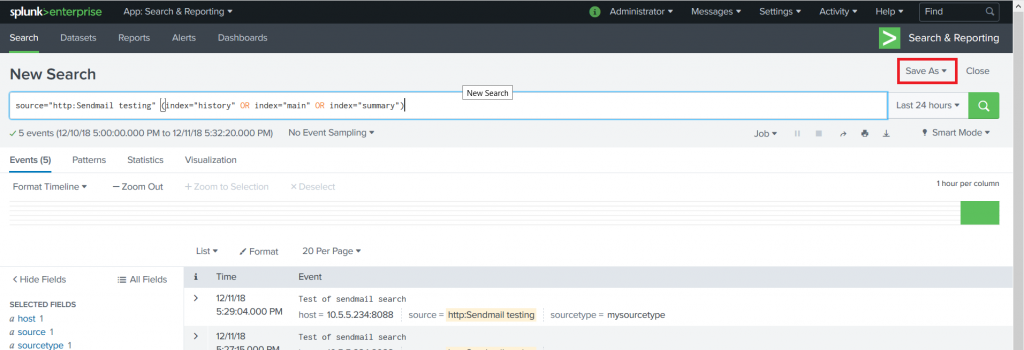
Now create a search for which you want to post data into your Teams channel. Click “Save As” and select “Alert”
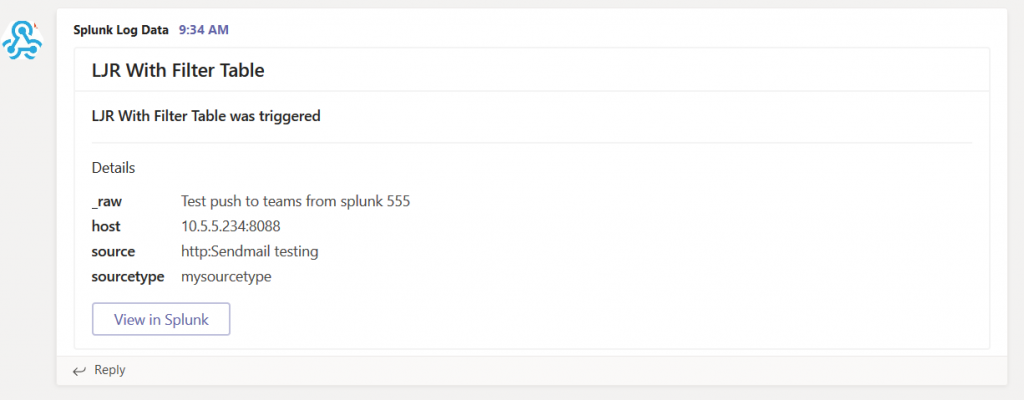
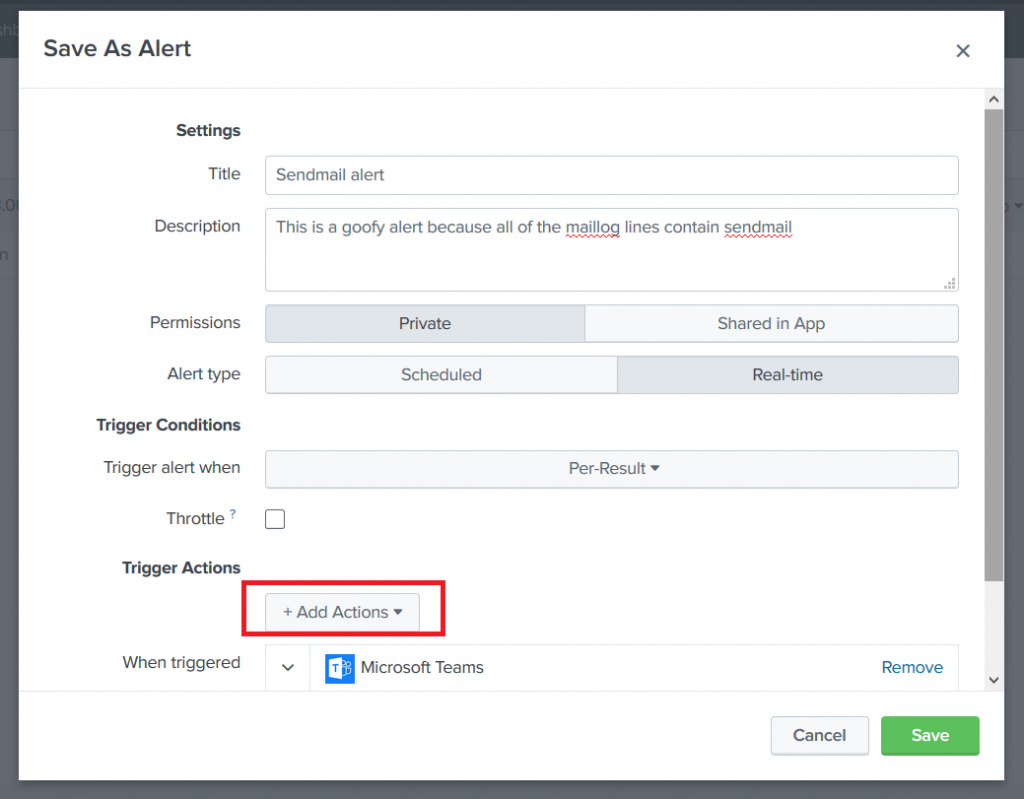
Provide a title for the alert — you can use real-time or scheduled alerts. Once you’ve got the alert sorted, select “Add Actions” and select the Teams webhook action (or the generic webhook action if you intend to use that one). Paste in the URL from your Teams channel webhook and click “Save”.
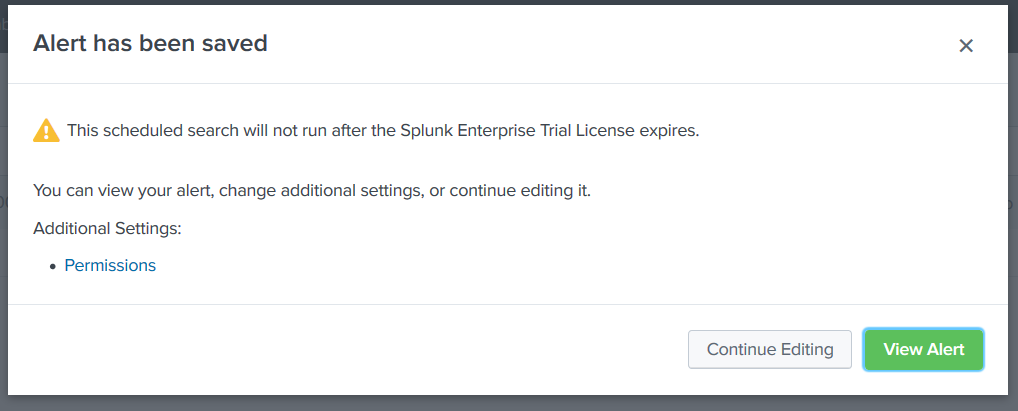
You”ll see a confirmation that the alert has been saved. Close this.
Now you would think you’d be ready to use it … but wait. Neither one works out of the box. In the Splunk log, you see error 400 “Bad data” reported.
For the default webhook app, edit the Python script (/opt/splunk/etc/apps/alert_webhook/bin/webhook.py in my case). Find the section where the JSON body is built. Teams requires a summary or title within the POST data. I just added a static summary, but you could do something fancier.
body = OrderedDict( sid=settings.get('sid'), summary='LJRWebhook', search_name=settings.get('search_name'), app=settings.get('app'), owner=settings.get('owner'), results_link=settings.get('results_link'), result=settings.get('result')
For the Teams-specific webhook, edit the Python script (/opt/splunk/etc/apps/alert_msteams/bin/teams.py in my case) and find the section where the facts list is populated. There’s too much data being sent through. There’s probably a way to filter it out in Splunk, but I don’t know how 🙂
The right way to do it is select the most important items from settings.get(‘result’).items that you want to be displayed within Teams and populate facts with those elements. I used a new list, strWantedKeys, to determine which keys should be added to the facts list. The quick/ugly way is to just take the first n items from the result items (settings.get(‘results’).items()[:7] gets seven … 8 produced a ‘bad payload received by generic incoming webhook’ error from Teams.
try: settings = json.loads(sys.stdin.read()) print >> sys.stderr, "DEBUG Settings: %s" % settings url = settings['configuration'].get('url') facts = [] strWantedKeys = ['sourcetype', '_raw', 'host', 'source'] for key,value in settings.get('result').items(): if key in strWantedKeys: facts.append({"name":key, "value":value}) body = OrderedDict(
On my home domain, I’ve always added an access control entry to prevent this from happening … it’s really easy to double-click and be in rename mode or drag and drop an OU into a new location. I’ve always considered this to be a bit of paranoia on my part — not like anyone’s routinely screwing up entire OU’s.
Until they are. We’ve had significant two outages at work caused by unintentional changes to Active Directory organizational unit names. Partially to avoid wide-spread outages due to something that’s fundamentally silly and partially because any widespread outage requires a root cause analysis that includes some action you’ve taken to prevent whatever from happening again we’re going to implement the same permission tweak at work now.
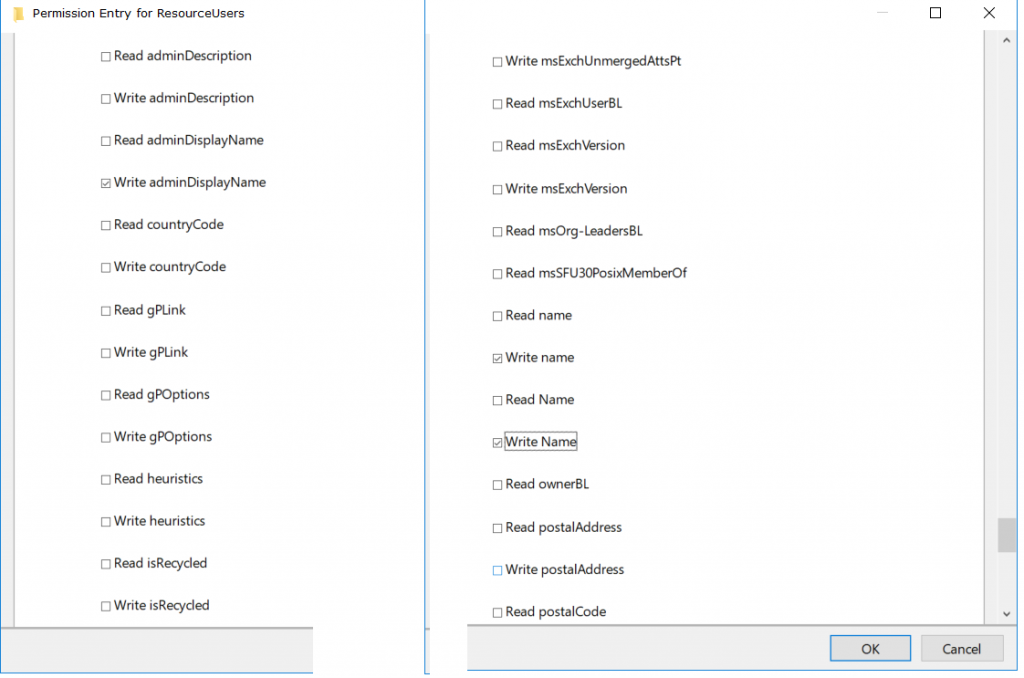
Since it’s not just me who has wanted/needed this permission, figured I would publish how I’ve got the permissions set:
No idea why the GUI shows name and Name instead of rdn and CN respectively. But I’ve denied write for adminDisplayName, rdn, and cn.
Just like the “prevent accidental deletion” checkbox is a bit of a pain when you want to delete an OU, this is inconvenient if you want to rename or move OUs. The first step is to remove the permission, then you can make your change, and then you’ve got to re-apply the permission. Slight inconvenience, but having the entire company failing LDAP authentications (where the base DN no longer finds the users) is a massive inconvenience too.
Ran out of disk space on the OUD partition (don’t let people turn on debug logging!!). Easily fixed — stop service, remove big log file, start again. Unfortunately that “start again” wasn’t as easy as it could have been. Server startup fails. It says the cryptomanager failed to publish the instance-key-pair in ADS …. which, Oracle says means you get to recreate the single instance. Honestly, this isn’t a horrible process since I’ve got a backup of the directory. But I’d rather not spend the next hour messing around with the server.
The underlying problem is that the admin partition didn’t dump out to its storage file (full disk), so admin-backend.ldif is a 0-byte file. Now, had the directory been running when I noticed this … I could have dumped the cn=admin data partition to another volume and copied the file in once I cleared up disk space. But I have a file-level backup … and it was easy enough to pull the file from last night back. Voila, one server online in a couple of minutes. And a good reminder for the future that a shutdown with a full disk … no good. I probably want to find something to free up a couple meg of space prior to shutting down the server. Extra-cautious option would be the MS Exchange approach of creating a few 5-meg files to ensure there’s space that can be freed up.
Added 06 Feb 2020: One of my colleagues encountered this problem again today, and it turns out you can copy the admin-backend.ldif from another server too. It may not be 100% — he cannot log into the server through the admin console. But he’s got a directory being served & no users complaining about an outage. It can get sorted properly later.
I often have trouble seeing the value behind cloud offerings — but most cloud migrations I’ve seen have done 1:1 replacement of locally hosted servers with cloud hosted servers. The first two years, the cloud hosted servers are cheaper (although that’s some dodgy accounting as we’re assuming no workforce changes as a result of outsourcing servers and depreciation of the owned asset is not considered). The third year, though, is a break-even point. General Depreciation System considers computers a five-year property, but there are accounting practices to handle fully depreciated assets. It remains on the balance sheet as a cost, it’s accumulated depreciation is listed as a accumulated depreciation contra asset item. When you *do* stop using the asset, the accumulated depreciation account is debited for the full depreciated amount, the fixed asset account is credited with its full cost. Point being I can continue using a computer asset after five years. Cloud hosted servers make financial sense for a company that tends towards “bleeding edge” implementations (buying the new whatever next year), but for a company that buys a server or application and then uses it for a decade … you’re simply turning capital expense into a greater ongoing operating expense. Which … good this year, but bad in the long term.
Now for a smaller company that doesn’t have a dedicated IT department, and that doesn’t actually need the capacity provided by a single modern server … externally hosting resources is financially beneficial. A web site, e-mail, chat-based customer service? All make sense to host externally. You don’t have to own half a dozen servers, make sure they’re backed up, etc. But I don’t see the cost benefit at enterprise levels unless (1) you want to build data centers close to customers without the expense of actually building a data center. For instance, opening your services to customers in the EU … getting a data center set up in, say, Germany isn’t a quick proposition. As your business grows, it may become “worth it” to invest money into a European data center. But cloud-hosted computers from some major provider who already has a presence there provides quick time-to-market and minimizes up-front cost. Some countries may have a laborious process for prospective businesses too — a process the cloud hosting provider has already navigated. Or you (2) plan a substantial workforce reduction. If someone else is backing up, patching, and monitoring systems … you don’t need people performing those duties. Since a cloud-hosting provider is able to leverage those employees across far more servers than you’d need — there’s a place where scale produces a cost benefit. But, strangely, I don’t see companies reducing IT operations staff after moving to the cloud. This may be a long-term goal to ensure the enthusiasm of staff for the move — it’s not particularly enticing to put six months of work into a project that ensures my job goes away. Or this may just be a thing — move to the cloud and still have twenty ops employees.
When we began allowing users to initiate password changes in Active Directory and feed those passwords into the identity management system (IDM), it was imperative that the passwords set in AD comply with the IDM password policy. Otherwise passwords were set in AD that were not set in the IDM system or other downstream managed directories. Microsoft does not have a password policy that allows the same level of control as the Oracle IDM (OIDM) policy, however password changes can be passed to DLL programs for farther evaluation (or, as in the case of the hook that forwards passwords to OIDM – the DLL can just return TRUE to accept the password but do something completely different with the password like send it along to an external system). Search for secmgmt “password filters” (https://msdn.microsoft.com/en-us/library/windows/desktop/ms721882(v=vs.85).aspx) for details from Microsoft.
LSA makes three different API calls to all of the DLLs listed in the NotificationPackages registry hive. First, InitializeChangeNotify(void) is called when LSA loads. The only reasonable answer to this call is “true” as it advises LSA that your filter is online and functional.
When a user attempts to change their password, LSA calls PasswordFilter(PUNICODE_STRING AccountName, PUNICODE_STRING FullName, PUNICODE_STRING Password, BOOLEAN SetOperation) — this is the mechanism we use to enforce a custom password policy. The response to a PasswordFilter call determines if the password is deemed acceptable.
Finally, when a password change is committed to the directory, LSA calls PasswordChangeNotify(PUNICODE_STRING UserName, ULONG RelativeId, PUNICODE_STRING NewPassword) — this is the call that should be used to synchronize passwords into remote systems (as an example, the Oracle DLL that is used to send AD-initiated password changes into OIDM). In our password filter, the function just returns ‘0’ because we don’t need to do anything with the password once it has been committed.
Our password filter is based on the Open Password Filter project at (https://github.com/jephthai/OpenPasswordFilter). The communication between the DLL and the service is changed to use localhost (127.0.0.1). The DLL accepts the password on failure (this is a point of discussion for each implementation to ensure you get the behaviour you want). In the event of a service failure, non-compliant passwords are accepted by Active Directory. It is thus possible for workstation-initiated password changes to get rejected by the IDM system. The user would then have one password in Active Directory and their old password will remain in all of the other connected systems (additionally, their IDM password expiry date would not advance, so they’d continue to receive notification of their pending password expiry).
While the DLL has access to the user ID and password, only the password is passed to the service. This means a potential compromise of the service (obtaining a memory dump, for example) will yield only passwords. If the password change occurred at an off time and there’s only one password changed in that timeframe, it may be possible to correlate the password to a user ID (although if someone is able to stack trace or grab memory dumps from our domain controller … we’ve got bigger problems!
The service which performs the filtering has been modified to search the proposed password for any word contained in a text file as a substring. If the case insensitive banned string appears anywhere within the proposed password, the password is rejected and the user gets an error indicating that the password does not meet the password complexity requirements.
Other password requirements (character length, character composition, cannot contain UID, cannot contain given name or surname) are implemented through the normal Microsoft password complexity requirements. This service is purely analyzing the proposed password for case insensitive matches of any string within the dictionary file.
Oh no, I didn’t mean to delete THAT!!! Sure, it asked me five times if I was sure that I was sure … and maybe that’s part of the problem – I see so many “are you sure” messages that I click OK a little too easily. Well, they say to err is human. And I must be exceptionally human ? Sometimes recovering my data requires a sheepish call to the Help Desk. But did you know you can recover deleted Teams channels?
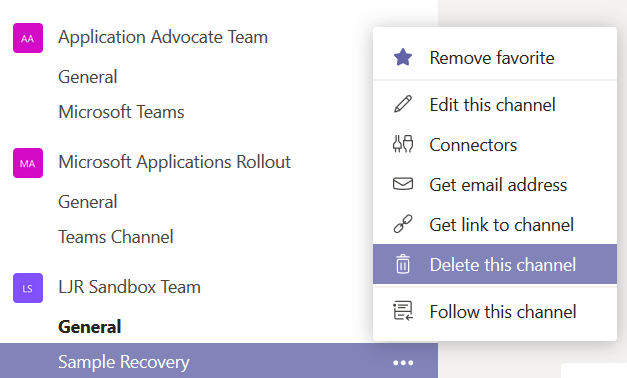
I used the hamburger menu next to a channel to delete it. Oops!
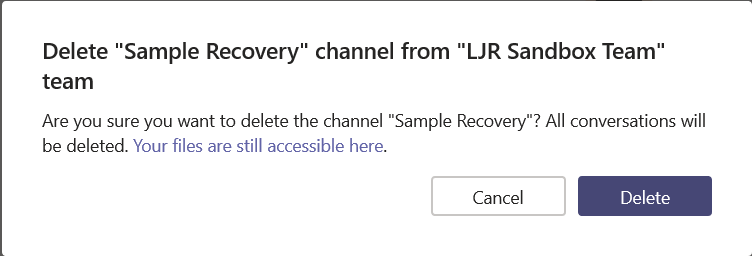
I even read the first few words of the “are you sure” dialogue before clicking the “Delete” button. Except … oops! I didn’t want to delete that channel!
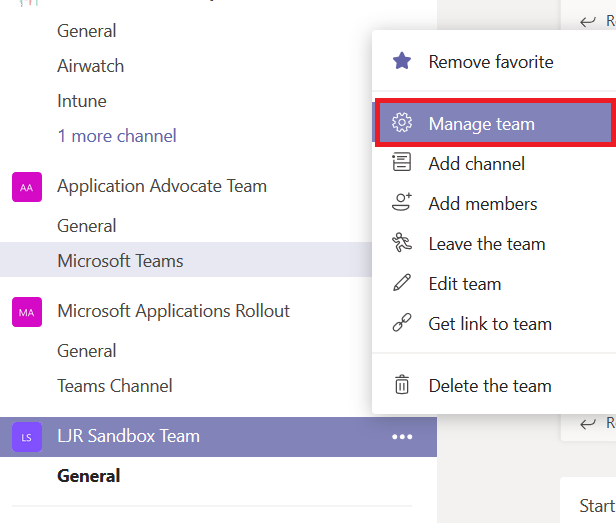
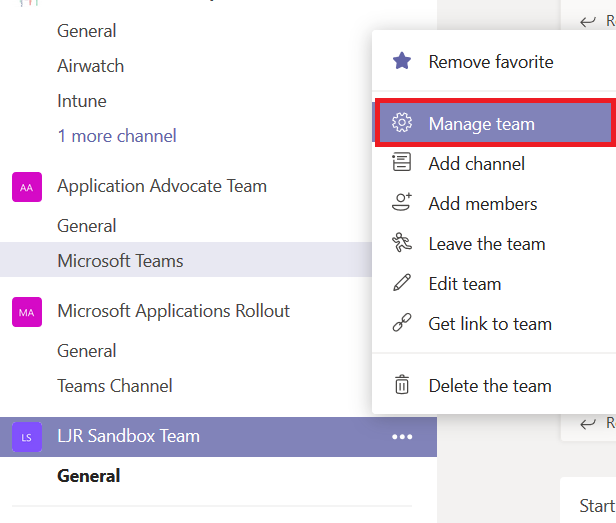
You can recover the channel immediately, all by yourself. Even if you’re not a team owner. From the hamburger menu next to the team, select “Manage team”.
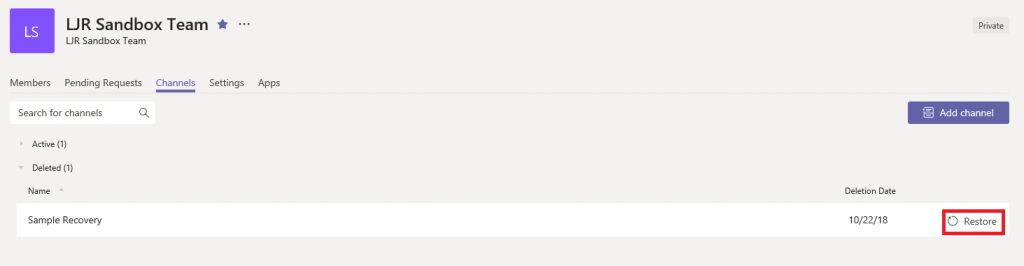
On the Team management page, select “Channels”. You can expand “Deleted” and see the channel you just removed. Click “Restore”
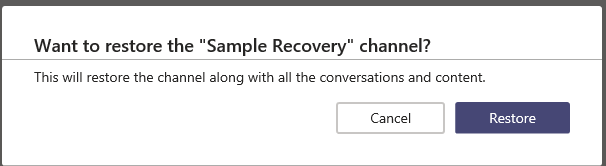
Yet another prompt … click “Restore” again.
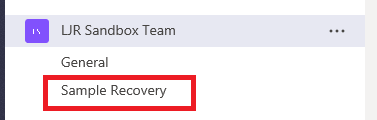
Voila, the channel is back. Along with all its content. Whew!
Just because channel recovery is self-service doesn’t mean no one will know that you’ve mis-clicked. The channel deletion event which appears in the “General” channel … well, it’s still there. You can up-vote a request for enhancement on Microsoft’s site … but it’s not like no one will every know about your mistake.
When you create a new Team, members can create new channels, delete channels, add apps … they can do a lot of things. Did you know much of that is configurable? You can create a Team where individuals receive but cannot respond to posts. You can restrict your Team so only owners can remove channels.
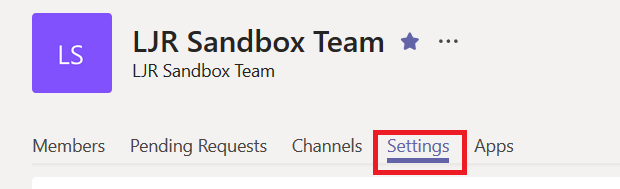
From the hamburger menu next to your Team, select “Manage team”
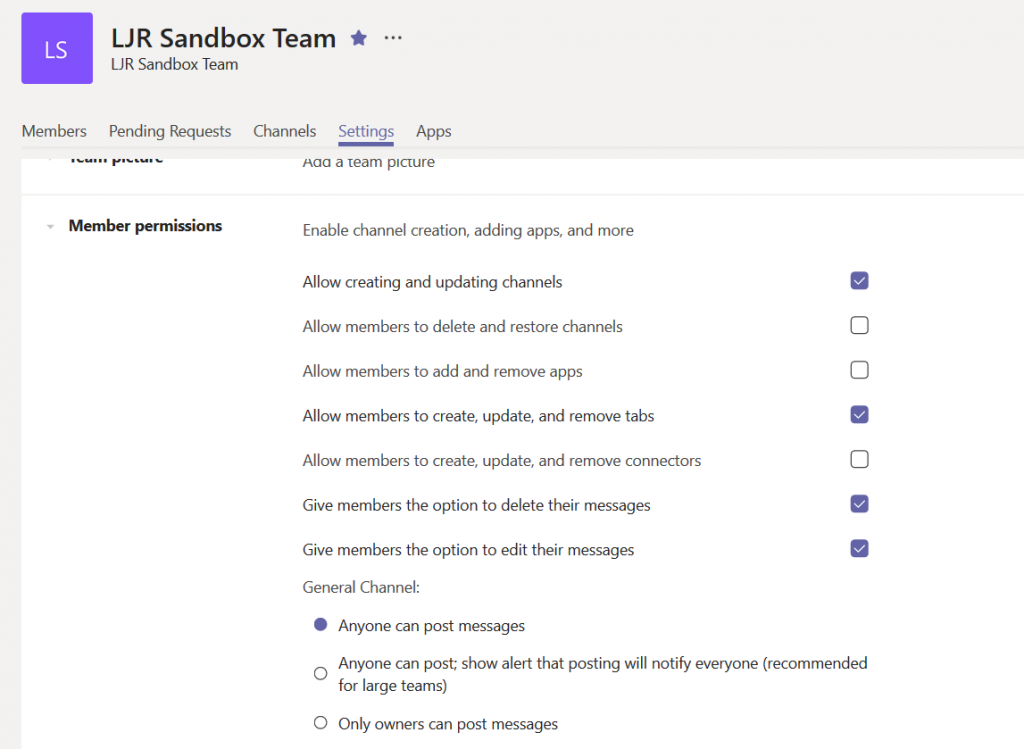
On the Team management page, select the “Settings” tab.
Expand the “Member permissions” section. Now uncheck any permission you want to restrict to Team owners. There’s even a radio button near the bottom of this section so only Team owners can post to the “General” channel (if that’s the only channel, and members are prohibited from creating their own channels, you’ve got a broadcast-only Team space)
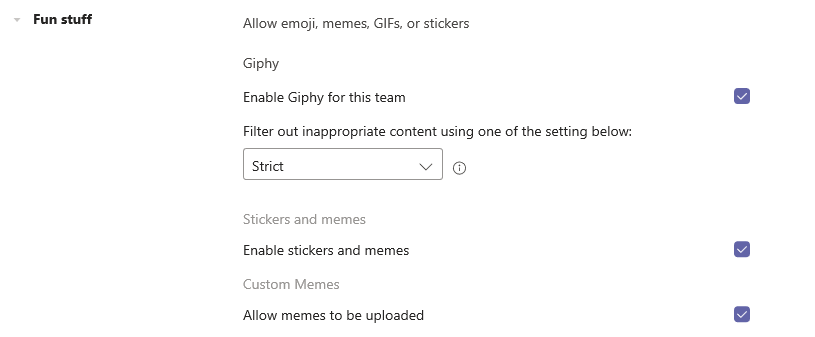
Scroll down and expand “Fun stuff” … you can prevent Gliphy content from being used in the Team (or change the filter used to determine which Gliphy content is appropriate), disable stickers, and disable memes.
Since I usually do not install X11 ‘stuff’ on my Linux hosts — using the console interface — I do not have any experience installing kernel updates on “desktop” type systems. Evidently, the best practice is to drop out of the GUI into what I’d call init 3 then install the kernel updates. You can get random hangs and malfunctions when you attempt to update the kernel whilst in the graphic console.