This past week, I’ve been reading about how Musk expects “dedication” from employees like 87 hour work-weeks and somehow that’s OK because it’s nothing he doesn’t do himself. I’m sure it’s willful ignorance, but how can he not see the difference between the owner of a company putting 80+ hours a week into their company and the person whose 40 hours his company bought being expected to donate another 40+ hours a week to his cause?! Does he get angry at the steel manufacturer because they only deliver five tonnes when he ordered and paid for five tonnes?
Category: Business
Why doesn’t everyone do this — non-working hours clarification
I like that Microsoft has added “they are x hours behind you” to individual profiles, but that assumes people all work 8-5 in their local time. Which isn’t the case, so I’ve been introducing myself to new people that I need to engage in meetings including something like “I work in the Eastern time zone but am generally available until about 6PM Eastern if that’s better for you” & asking for a similar response from them. I know some people who live in the Central, Mountain, or Pacific time zones but work 8-5 Eastern. I know others who live in the same area work 9-6 or 11-8 Eastern. We have overseas contractors who work from 3:30 AM to 12:30 PM Eastern, and others who who start working around 10 AM.
Seems like it would make collaborating with others easier if we all had recurring appointments to clarify our non-working hours. A recurring each-weekday appointment like below — away so it doesn’t look like I’m just booked solid at dark-o-clock, recurring, and no reminder (because that would get super annoying). And maybe a recurring weekly one from whatever PM on Friday through whatever AM on Monday if there are a statistically significant of people who’d be working T-Sat or Sun-Thur.
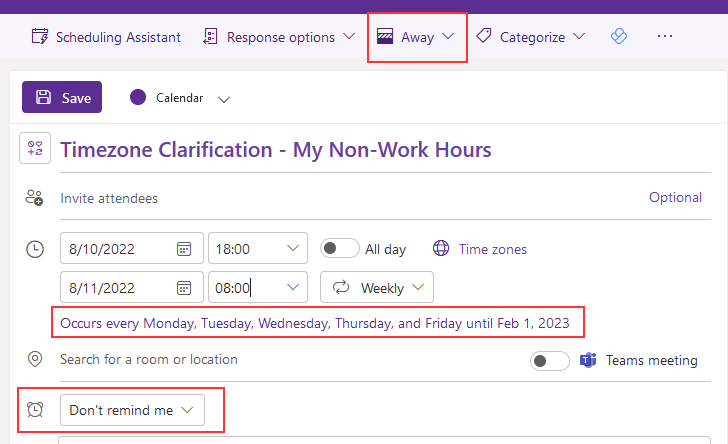
Doesn’t really provide much value implemented in a small group – you generally get a good idea of when your immediate coworkers are working. But it would help a lot reaching out to other groups!
Reducing Customer Service Calls Wait Time
As we finally managed to get through the Chase IVR only to be told that the expected wait time is ten minutes … in addition to the eight minutes we’ve already spent trying to convince their IVR that we didn’t need to pay our bill or check out balance, I wonder how feasible it would be to drop the caller into the CS rep queue when the call is first answered, let them spend some of their hold time telling the IVR what exactly they need (possibly moving their placeholder to another queue if, say, they seem to want tech support and not general CS), and either deleting the placeholder because the caller’s problem actually got resolved by the computer or adding a “ready to talk” attribute to the placeholder so the call is ready to transfer out to the next available agent. Bummer that I haven’t done IVR call route development in decades because I’d love to prototype that logic and see if it actually works (it’s possible we’d just end up with hundreds of pointers to people who are still navigating the IVR instead of actually reducing wait times).
Idea – AR in Store App
Use augmented reality in company app — customers use the apps as they shop to find discounts on in-store products and retailers can track where shoppers are (how long individuals stop at which section, what path they take). Customers could use the app to search the store, navigate around, and maybe even find Easter eggs / bonus deals exclusive to the app.
The hazard of curbside pickup
I’ve had an ongoing problem with the curbside grocery pickup — it’s a great time saver (and basically eliminates off-list purchasing / impulse shopping), and I get the limitations of asking someone else to think for you (I add a note that indicates the exact number of large/small *bunches* of bananas I actually want whilst ordering unit “1” banana, and I know they are not just going to figure it out and get jicama when they’re out of celery root). My problem is that the quality of the food that ends up in my order is absolutely not something I’d have bought. I won’t buy mushy, rotten oranges. Or visibly moldy strawberries. Or meat with huge chunks of fat. I’ve taken to putting in a big order of shelf-stable staples for pickup a few times a year and selecting the perishables myself. And accepting the time / quality trade-off when I ask them to select my produce for me.
Thought that was a problem unique to the grocery store, but we picked up chicken chow from Tractor Supply today. Last time, the 6 pound bag that was brought out instead of a 40 pound bag was really obvious. And quickly corrected. This time? We bought two bags of food — the first one was fine. Upon lifting the first bag out of the car, though, I discovered the second bag. A bag which looks like it was dragged across the warehouse floor and then taped up to retain whatever was left in the bag. This certainly isn’t a bag someone would have put into their cart at full price. I’ve seen other companies slap a discount sticker on a mostly full taped up bag. Unloading the ripped bag of something close to 40 pounds of chicken food, at full price, on a curbside pickup? Kinda sucky!
Luckily, Tractor Supply has excellent customer service policies. I used the ‘contact us’ form to tell them about the problem — and, yeah, I could have just brought it back to the store. But … had I been in the car park when I noticed the bag, I certainly would have asked for the bag to be swapped out. A couple extra minutes was worth it to avoid whatever contaminants got into the bag and whatever amount of food fell out of the bag. Half an hour of driving? Not worth it for what’s probably some warehouse dirt and maybe a pound of missing food. Within a few hours, a customer service rep rang be to apologize for the mangled bag. He refunded the purchase price and issued a gift card for our inconvenience. That’s more than fair.

Better Business Bureau
There are a few scenarios where the advertised protection a process offers are effectively worthless — Ebay disputes won’t refund shipping charges or require you to pay additional shipping to return an item, so shorting the customer by less than the shipping cost makes winning your dispute worthless. The 1970’s Fair Credit Billing Act gives you the right to dispute charges up to 60 days after the charge — but, when I ordered a CSA membership in September that started the following March … that window precluded a simple charge-back when the CSA claimed I was not on their list. I expect this window is why people get upset when companies finalize the charge before shipping the product.
Outside of the FCBA contest period, there’s not a whole lot you can do. Small claims could be a route, but that is less effective for inter-state transactions. Some company in Texas doesn’t really care that they’ve got a judgement against them in Ohio. Ohio doesn’t have a lot of power to force payment, either. Traveling to the state with more direct jurisdiction is expensive, and you’re not likely to reclaim damages incurred in obtaining the judgement (i.e. the settlement is not apt to cover your hundred dollar refund, three hundred dollar plane ticket, thousand dollars in hotel charges, and couple hundred bucks for a rental car).
That’s where we were with Keg Factory. We’d gotten a DigiBoil with an inaccurate temp reading. And been told by KegLand, the manufacturer, that the unit isn’t meant for mashing so isn’t designed to have an accurate temperature reading. (Asking why there’s a mashing kit for the not designed for mashing product didn’t yield any illuminating answer) … the owner of Keg Factory told us the product didn’t seem to be a good match for our needs (true, but the advertised function of the product certainly met our requirements!) and offered a shipping label to return the thing. Seemed like a good idea to stop wasting time on a product if the manufacturer says it’s not good enough for its intended purpose. We confirmed they weren’t looking to add a restocking fee or otherwise charge us — a full refund was what was on offer. Yup, that’s it. So we packed up the thing, shipped it off, and confirmed delivery. That was March. We proceeded to contact them looking for our refund. Calls routed to voicemail. No return e-mails. Online chat where we’re the next in queue for hours. When we did get through to someone, we’d be told someone would look at it that day. And still no refund.
As a last ditch effort, we filed a complaint with the Better Business Bureau. The Austin office concurred that our problem fell into their purview and forwarded the complaint on to the vendor. We got a refund notice within a few hours! It took a few days for the refund to clear through to my credit card, but a complaint with the BBB accomplished in three or four days (days where we didn’t do anything) than months of calls / online chats / e-mails managed. Sad that it seems to take publication of poor service to correct a problem … but I’m exceptionally glad to have this saga over.
Air Popper
We got a air popper to make popcorn (we’d made some really good caramel corn a few night previously, and really want to make some more … plus it’s just easier to use an air popper than to pop the kernels on the stove). Picked Presto’s 04820 (which is cheaper and , evidently, the same as the 04821 but without the popcorn company’s logo on it) – a 1475 Watt air popper). It works well, but there’s a strange design decision — no on/off switch. Obviously, we can unplug the thing and plug it in again when we’re ready to use it. I expect a majority of the use cases involve the popper being put into a cupboard somewhere when not in use anyway — so the machine is going to be unplugged after each use.
I expect this is a trend we’ll see in small appliances — it’s a component cost the company saved, reduced assembly time, and a point of failure is eliminated.
Simplified Outage Reporting
We’ve lost power the past few days — I think that’s because the forestry crew is clearing a few trees that are down on the power lines, but I don’t know so we report the outage. First Energy has a really cool way of reporting outages — you use SMS to register your phone with your account. Once the phone is registered to an account, you can text “OUT” to their short code. There’s a short code to register for outage notifications, status alerts. So when the power went out today, it took about three seconds to report the outage. No walking through the IVR to report the outage online. I hope to see more companies doing this in the future.
Cloudy ROI
I often have trouble seeing the value behind cloud offerings — but most cloud migrations I’ve seen have done 1:1 replacement of locally hosted servers with cloud hosted servers. The first two years, the cloud hosted servers are cheaper (although that’s some dodgy accounting as we’re assuming no workforce changes as a result of outsourcing servers and depreciation of the owned asset is not considered). The third year, though, is a break-even point. General Depreciation System considers computers a five-year property, but there are accounting practices to handle fully depreciated assets. It remains on the balance sheet as a cost, it’s accumulated depreciation is listed as a accumulated depreciation contra asset item. When you *do* stop using the asset, the accumulated depreciation account is debited for the full depreciated amount, the fixed asset account is credited with its full cost. Point being I can continue using a computer asset after five years. Cloud hosted servers make financial sense for a company that tends towards “bleeding edge” implementations (buying the new whatever next year), but for a company that buys a server or application and then uses it for a decade … you’re simply turning capital expense into a greater ongoing operating expense. Which … good this year, but bad in the long term.
Now for a smaller company that doesn’t have a dedicated IT department, and that doesn’t actually need the capacity provided by a single modern server … externally hosting resources is financially beneficial. A web site, e-mail, chat-based customer service? All make sense to host externally. You don’t have to own half a dozen servers, make sure they’re backed up, etc. But I don’t see the cost benefit at enterprise levels unless (1) you want to build data centers close to customers without the expense of actually building a data center. For instance, opening your services to customers in the EU … getting a data center set up in, say, Germany isn’t a quick proposition. As your business grows, it may become “worth it” to invest money into a European data center. But cloud-hosted computers from some major provider who already has a presence there provides quick time-to-market and minimizes up-front cost. Some countries may have a laborious process for prospective businesses too — a process the cloud hosting provider has already navigated. Or you (2) plan a substantial workforce reduction. If someone else is backing up, patching, and monitoring systems … you don’t need people performing those duties. Since a cloud-hosting provider is able to leverage those employees across far more servers than you’d need — there’s a place where scale produces a cost benefit. But, strangely, I don’t see companies reducing IT operations staff after moving to the cloud. This may be a long-term goal to ensure the enthusiasm of staff for the move — it’s not particularly enticing to put six months of work into a project that ensures my job goes away. Or this may just be a thing — move to the cloud and still have twenty ops employees.
Agile Methodology Is Not Anarchy
For the past several years, my employer has been moving toward an Agile development methodology. There are some challenges when mapping this methodology into operations because it’s not the same thing; but, surprisingly, those are not where I have experienced challenges. The biggest challenge during this transition is some of my coworkers seem to think the methodology is that there are no rules.
A friend of mine, a fairly eccentric history professor, used to say that a little knowledge is a dangerous thing but you’ve got to emphasize LITTLE. And it seems like we’re encountering a situation where Phil’s emphasis holds true: the only thing garnered from from Agile training is that the documentation and process from waterfall projects are no more. But breaking away from the large-scale view of a P.R.O.J.E.C.T. for Agile development is a bit like breaking a monolithic application out into microservices — it still needs to do all of the same ‘stuff’, it just does it differently. And there are still policies and procedures — even a microservice team is going to have a coding standard, a process for handling merges, a way of scheduling time off, and some basic idea of what their application needs to accomplish. Sure, the app’s design will change incrementally over time. But it’s not an emergent property like chaos/complexity theory.
Maybe the “what Agile means to me” mentality comes from failing to clearly map a development methodology into an operations framework. Maybe it’s just a good excuse to avoid components of work that they do not enjoy. To avoid “agile operations” becoming “no boring planning stuff!!!”, I’ve outlined ways in which the Scrum methodologies the company wishes to adopt can be used to streamline operations. It helps that our group is reorganizing into an operational/support group and an architecture/design group — I see a lot of places within the operations team where Scrum approaches make sense.
Backlog — prioritizing the ticket queue like a backlog and having support staff constantly pulling from the top of the list — not only is this an awesome way to avoid the guy who scans the queue for the easy jobs, but it ensures the most important problems are being resolved first. A universal set of stakeholders does not exist for the ticket queue — someone whose ticket is ranked fifteenth on the list may disagree, and they are welcome to add details explaining why the issue is more impacting that it seems on its face. But 90% or more of our tickets are “Sev3” — which basically means both “we want it done ASAP” and “it isn’t a wide-spread high impact outage”. Realistically, dozens of tickets do not have the exact same time constraint and impact. There is extra work for management in converting a ticket bucket into an ordered backlog, but the payoff is that tickets are resolved in an order that correlates to the importance of the issue. In addition to the ticket queue, routine maintenance tasks will be included in the backlog. And prioritized accordingly.
Very short sprints — while developers moving from Waterfall to Agile might start from a month (or two) long sprint and trim weeks as they evolve into the process, operations starts from the other end of the spectrum. Our norm is to grab a ticket, sort it, then look at the queue and grab another one. We are planning for hours, maybe a day or two. This means we might establish application access on Tuesday that isn’t needed until next Monday. Establish a sprint that lasts a week, and use the backlog to get tickets that have lower priority (either because the impact is lower or because resolution is not needed for a week) included in the sprint. Service interruptions, SEV1 and SEV2 tickets, will occur and should be assumed in the sprint planning (i.e. either take enough work that you think it will just get done with no service interruption tickets and accept that some tickets from the sprint will be incomplete or leave some space for service interruption tickets and have staff pull “bonus” tickets from the top of the backlog if they have no work toward the end of the sprint).
Estimation — going through the tickets and classifying each incident as a quick little task, something that will take a few hours, or a significant undertaking facilitates in sprint planning. It’s difficult to know how many tickets I can reasonably expect to include in a sprint if I cannot differentiate between a three minute config change and a three day application rollout.
Multi-tasking — Implementation, support, and ticket resolution tasks are no longer a big bucket of work that individuals attempt to multi-task to complete. There are distinct tasks that are completed in series. Some tickets require information from the user; put the ticket on hold until a response is received and move on to the next unit of work.
Velocity — historic data based on time estimates cannot be generated, but simple number of tickets per week pre- and post- can certainly be compared. And going forward, ticket counts can be weighted by estimation values.
Stand-ups are a bit of a mental sticking point for me. I can conceive the value of spending a few minutes reviewing what you’ve done, what you plan on doing, and ensuring there is a ready forum to discuss any sticking points (maybe someone else has encountered a similar situation and can offer assistance). Stand-ups could include a quick discussion of any priority shifts (escalations, service interruptions) too. *But* my experience with stand-ups has been the attendance test variety — stand-ups that were used to hurt individuals who didn’t make it to the office by 08:00. Or those who weren’t around at 16:50. I don’t think it’s reasonable to ask someone who got into an issue and worked until 7P to show up at 8A the next day. I also don’t think it is reasonable to expect someone who came in at 6A to continue working until 5P. Were a stand-up scheduled in the middle of the day, I might feel differently about them.