To automatically update files from your repository on your server, use a release pipeline. For convenience, I use deployment groups to ensure all of the servers are updated.
Creating a deployment group
Under the Project, navigate to Pipelines and “deployment groups”. Click “New” and provide a name for the deployment group.
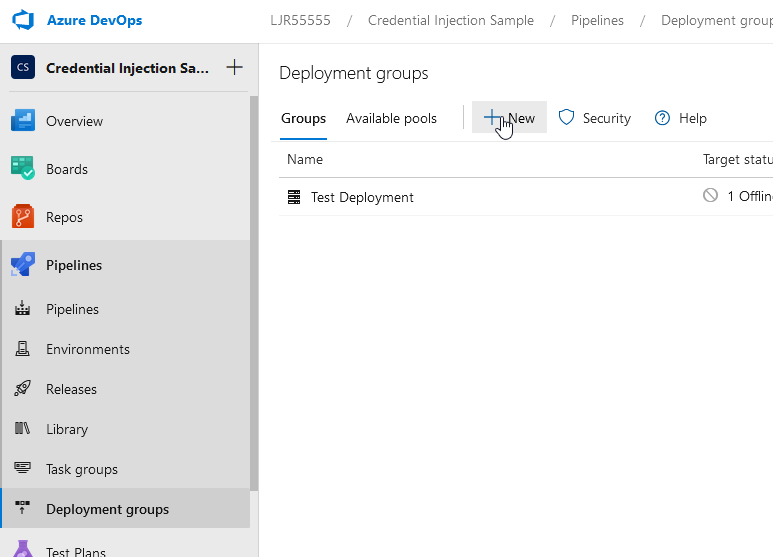
Now click into the deployment group and select “Register”

Since I have a Linux server, I changed the “Type of target to register” drop-down to “Linux”. Copy the command and run it on your server (I don’t run literally what MS provides – I break it out into individual commands so I can make a folder named what I want it to be named and just run the part of the command that registers a service with systemctl.
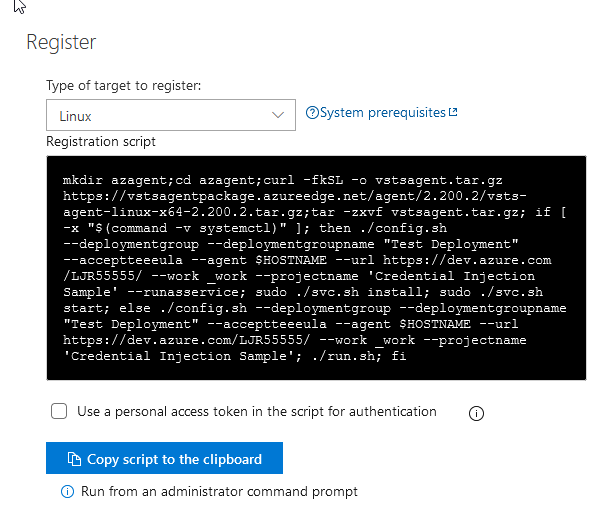
Run the agent – for demonstration purposes, I am using the run.sh script to launch the agent. This outputs details to my console instead of a log file.

If you have multiple servers to which you want to deploy the files, install and run an agent on each one.
Create the release pipeline
Now we will build the pipeline that actually copies files over to the agent. Under Pipelines, navigate to “Releases”. Select “New” and create a “New release pipeline”. Start with an empty job.
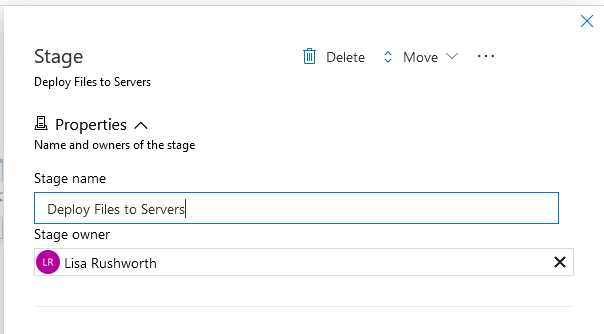
You’ll be asked to name the first stage of the deployment pipeline – here, I’m calling it “Deploy Files to Servers”. Close out of the Stage window to see the pipeline.
Click the “+ Add” next to Artifacts to link an artifact to the deployment

If you have a build pipeline, you can link that as the artifact. Since I am just copying files, I selected the “Azure Repo” and configured the test project that contains the files I wish to deploy to my servers.
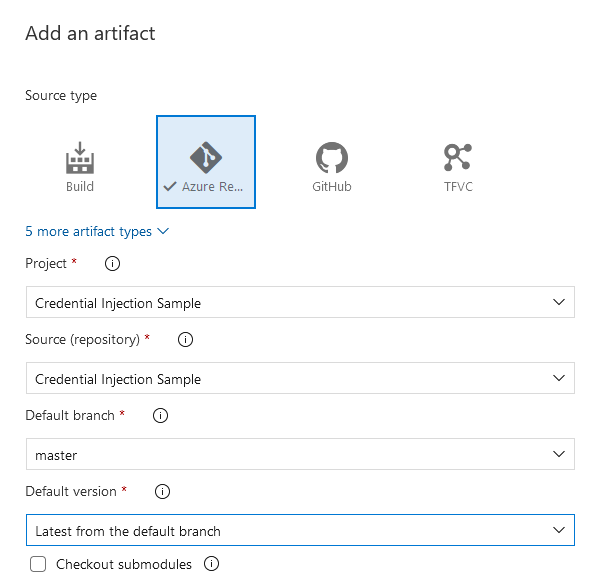
Click “Add”
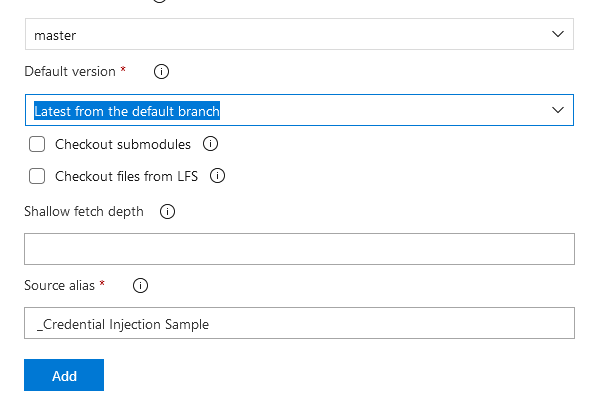
Back in the pipeline, click the “1 job, 0 task” hyperlink to create a file deployment task.
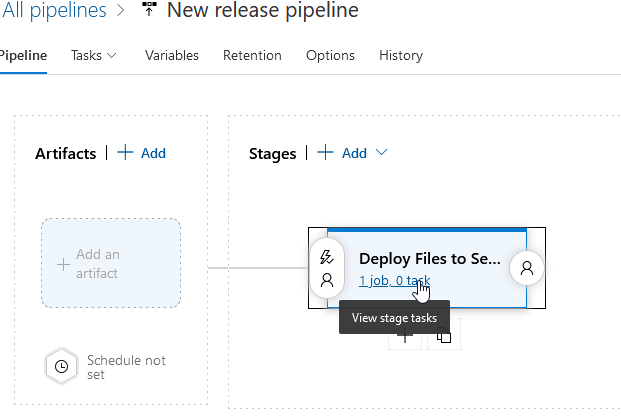
We don’t need the “Agent job”, so click on it and click “Remove”
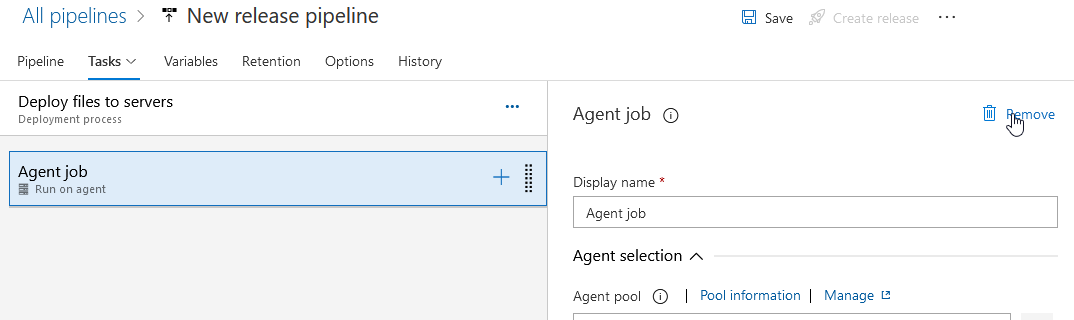
Select the hamburger menu next to “Deploy files to servers” and select “Add a deployment group job”
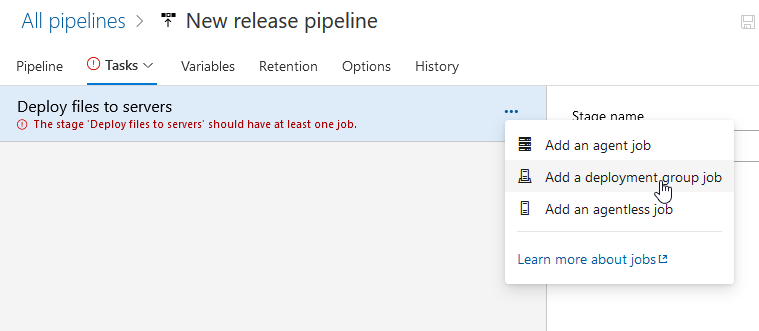
Click the “Deployment group” dropdown and select the deployment group that contains the servers to which you want to deploy files. You can add tags to limit deployment to a subset of the deployment group – I don’t do this, but I have seen instances where “prod” and “dev” tags were used and all servers in both the prod and dev environment were part of the same deployment group.
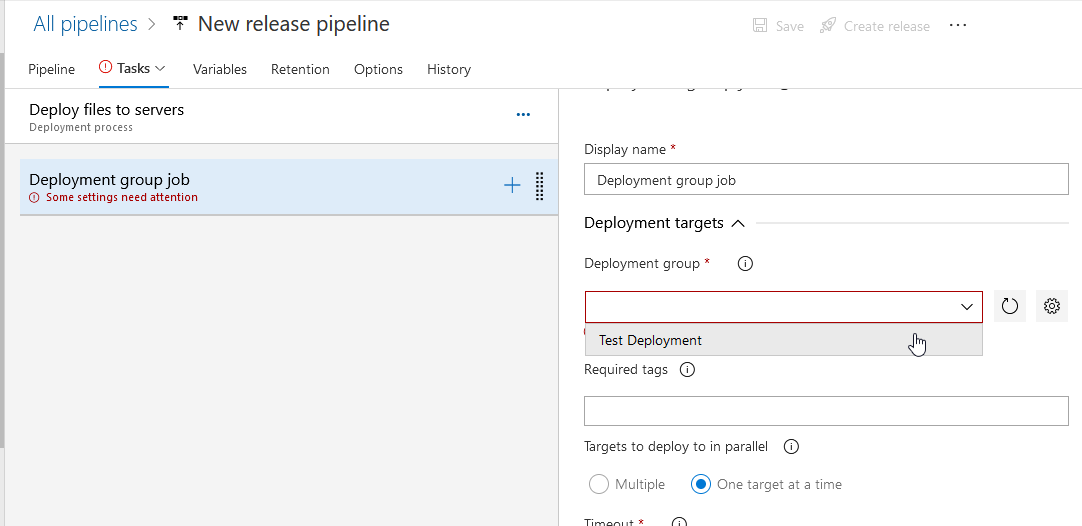
Click the “+” on the “Deployment group job” item to add a task.
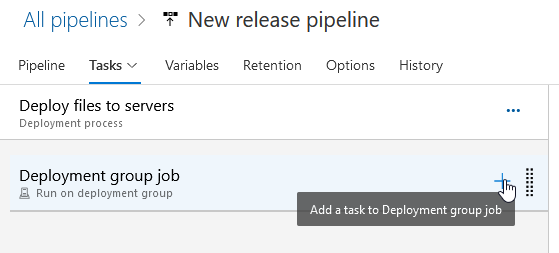
Find the “Copy files” task and click “Add” to create a task to copy files.
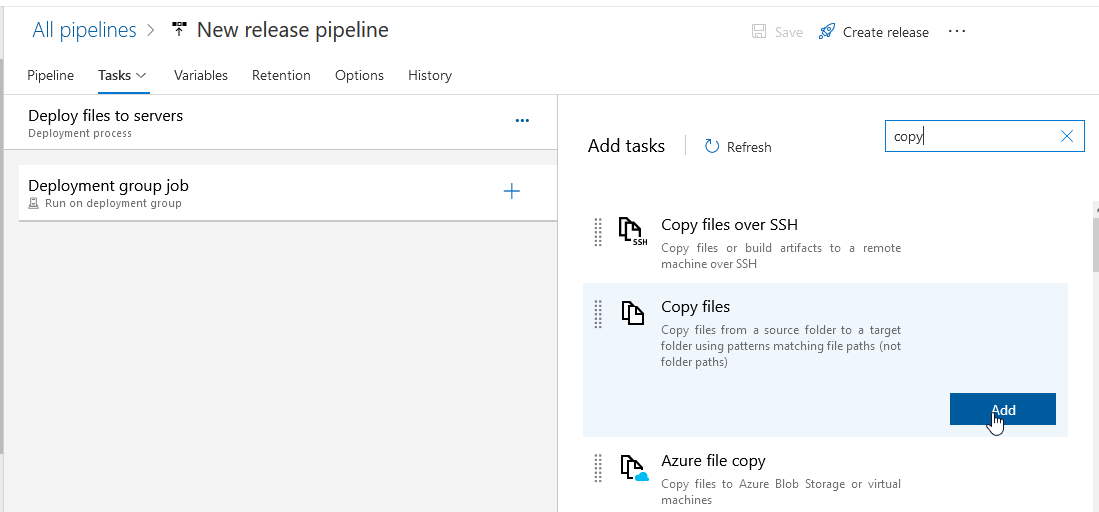
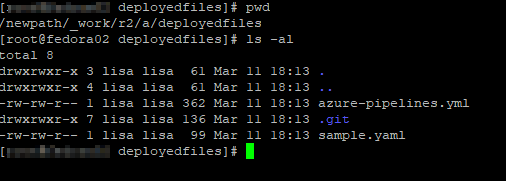
Click on the “Copy files to:” item to configure the task. The source folder is the Azure repo, and the target folder is the path on the server.
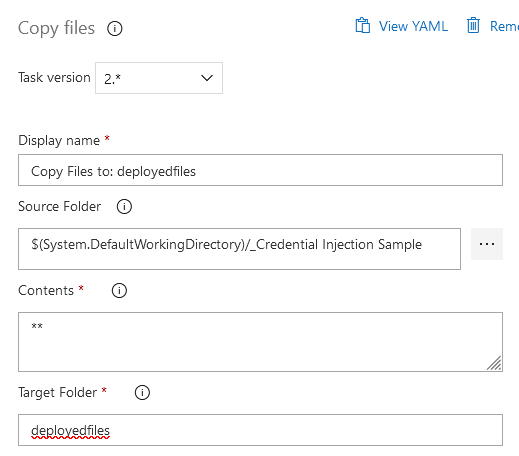
Click “Save” to save the task, then click “OK” to save the task.
Now create a release – click the “Create a release” button
ok
When the deployment runs, the agent will show the job running.
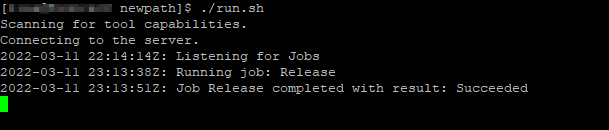
Once the deployment completes, the files are on the server.
Scheduling Release
In the pipeline, you can click on “Schedule set” to schedule new releases.
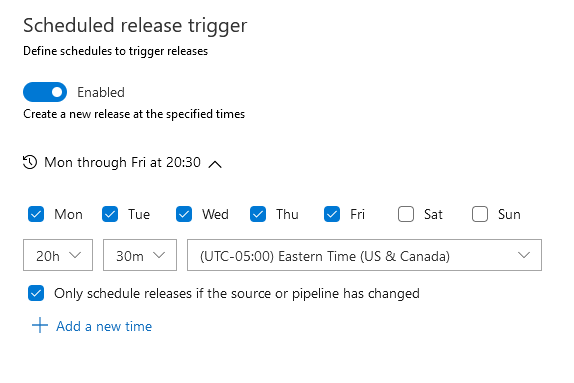
Enable the schedule, set a time – I select to only schedule the release if the source or pipeline has changed … if I’ve not updated files in the repo, there’s no need to redeploy the files. Remember to save your pipeline when you add the schedule.



Summary: Playlist items are not returned from searches initiated on my uPNP client. The playlist is visible when browsing the Gerbera web UI under Playlists->All Playlists->Playlist Name and Playlists->Directories->Playlists->Playlist Name
Action: In a uPNP client, search using the criteria
upnp:class = "object.container.playlistContainer" and dc:title = "Playlist Name",Expected Results: Playlist matching search criteria is returned
Actual Results: No results are returned
Investigation:
From the Gerbera debug log, the search being executed is:
SELECT DISTINCT "c"."id", "c"."ref_id","c"."parent_id", "c"."object_type", "c"."upnp_class", "c"."dc_title",
"c"."mime_type" , "c"."flags", "c"."part_number", "c"."track_number",
"c"."location", "c"."last_modified", "c"."last_updated"
FROM "mt_cds_object" "c"
INNER JOIN "mt_metadata" "m" ON "c"."id" = "m"."item_id"
INNER JOIN "grb_cds_resource" "re" ON "c"."id" = "re"."item_id"
WHERE (LOWER("c"."upnp_class")=LOWER('object.container.playlistContainer'))
AND (LOWER("c"."dc_title")=LOWER('Playlist Name'))
ORDER BY "c"."dc_title" ASC;
The playlists do not have a row in the grb_cds_resource table, so the “INNER JOIN” means the query returns no records.
I am able to work around this issue by manually inserting playlist items into the grb_cds_resource table
INSERT INTO grb_cds_resource (item_id, res_id, handlerType) VALUES (1235555,0,0);If I have some time, I want to test changing join2 to be a left outer join and see if that breaks anything.