The first chick hatched this evening — and three more followed throughout the night. We’ve got four little ones out of their eggs and a bunch of eggs (hopefully) to go.

The first chick hatched this evening — and three more followed throughout the night. We’ve got four little ones out of their eggs and a bunch of eggs (hopefully) to go.
Character filters are the first component of an analyzer. They can remove unwanted characters – this could be html tags (“char_filter”: [“html_strip”]) or some custom replacement – or change character(s) into other character(s). Output from the character filter is passed to the tokenizer.
The tokenizer breaks the string out into individual components (tokens). A commonly used tokenizer is the whitespace tokenizer which uses whitespace characters as the token delimiter. For CSV data, you could build a custom pattern tokenizer with “,” as the delimiter.
Then token filters removes anything deemed unnecessary. The standard token filter applies a lower-case function too – so NOW, Now, and now all produce the same token.
You can one-off analyze a string using any of the
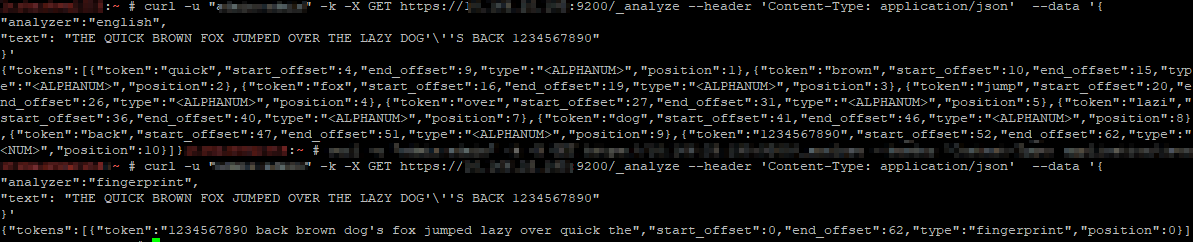
curl -u “admin:admin” -k -X GET https://localhost:9200/_analyze –header ‘Content-Type: application/json’ –data ‘
“analyzer”:”standard”,
“text”: “THE QUICK BROWN FOX JUMPED OVER THE LAZY DOG’\”S BACK 1234567890″
}’

Specifying different analyzers produces different tokens
It’s even possible to define a custom analyzer in an index – you’ll see this in the index configuration. Adding character mappings to a custom filter – the example used in Elastic’s documentation maps Arabic numbers to their European counterparts – might be a useful tool in our implementation. One of the examples is turning ASCII emoticons into emotional descriptors (_happy_, _sad_, _crying_, _raspberry_, etc) that would be useful in analyzing customer communications. In log processing, we might want to map phrases into commonly used abbreviations (not a real-world example, but if programmatic input spelled out “self-contained breathing apparatus”, I expect most people would still search for SCBA if they wanted to see how frequently SCBA tanks were used for call-outs). It will be interesting to see how frequently programmatic input doesn’t line up with user expectations to see if character mappings will be beneficial.
In addition to testing individual analyzers, you can test the analyzer associated to an index – instead of using the /_analyze endpoint, use the /indexname/_analyze endpoint.

Pipping!

The garlic has sprouted and is about a foot tall — I mulched around the plants to keep weeds down and retain soil moisture.

We tightened down all of the connections, stretched the plastic over the top, and tied it down.

Now we have a 26′ greenhouse ready to grow lettuce and house the tiny bird tractor.

Since the leaked draft overturning Roe v Wade was released, I’ve encountered a number of forums in which women are advocating we all delete any menstruation tracking apps. This seems, to me, like performance art meant as protest. Not an effective solution to the stated problem.
I get the point — people don’t want their data tracked in a place where the state can readily compel production of records. If they have reasonable suspicion that an abortion took place, they can get a warrant for your data. But deleting the app from your phone — that doesn’t actually delete the data on the cloud hosting provider’s side. Deleting the app has the same impact as ceasing to enter new data. Except you’ve inconvenienced yourself by losing access to your old data. Check if an account can be deleted — and learn what the details of ‘delete’ actually mean. In many cases, ‘delete’ means disable and then purge after some delta time elapses. What about backups? For how long would the company be able to produce data if they really needed to?
But before going to extremes to actually delete data, consider if the alternatives are actually any “safer” by your definition. If I were tracking my period on a little paper calendar in my purse or one pinned to the cork board in the rec room? They may get a warrant and seize my paper calendar too. And, really, you could continue to enter “periods” even if they’re not happening. There’s usually a field for ‘notes’ and you could put something in like ‘really painful cramping’ or ‘so many hot flashes’ whenever you actually mean “yeah, this one didn’t happen” — which would make the data the government is able to gather rather meaningless.
I made my own SCOBY without using kombucha — diced up some old apples and coated them in sugar. It worked! I just started my first batch of kombucha using tea and maple syrup.

There are a few ways to reset the password on an individual account … but they require you to have a known password. But what about when you don’t have any good passwords? (You might be able to read your kibana.yml and get a known good password, so that would be a good place to check). Provided you have OS access, just create another superuser account using the elasticsearch-users binary:
/usr/share/elasticsearch/bin/elasticsearch-users useradd ljradmin -p S0m3pA5sw0Rd -r superuser
You can then use curl to the ElasticSearch API to reset the elastic account password
curl -s --user ljradmin:S0m3pA5sw0Rd -XPUT "http://127.0.0.1:9200/_xpack/security/user/elastic/_password" -H 'Content-Type: application/json' -d'
{
"password" : "N3wPa5sw0Rd4ElasticU53r"
}
'
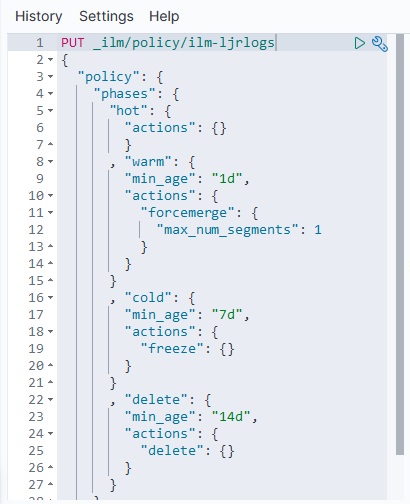
The following defines a simple data lifecycle policy we use for event log data.
Immediately, the data is in the “hot” phase.
After one day, it is moved to the “warm” phase where the number of segments is compressed to 1 (lots-o-segments are good for writing, but since we’re dealing with timescale stats & log data [i.e. something that’s not being written to the next day], there is no need to optimize write performance. The index will be read only, thus can be optimized for read performance). After seven days, the index is frozen (mostly moved out of memory) as in this use case, data generally isn’t used after a week. Thus, there is no need to fill up the server’s memory to speed up access to unused data elements. Since freeze is deprecated in a future version (due to improvements in memory utilization that should obsolete freezing indices), we’ll need to watch our memory usage after upgrading to ES8.
Finally, after fourteen days, the data is deleted.
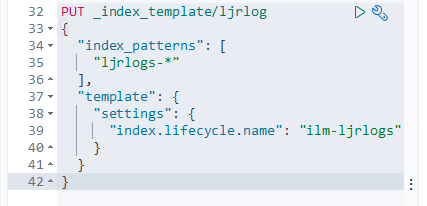
To use the policy, set it as the template on an index:
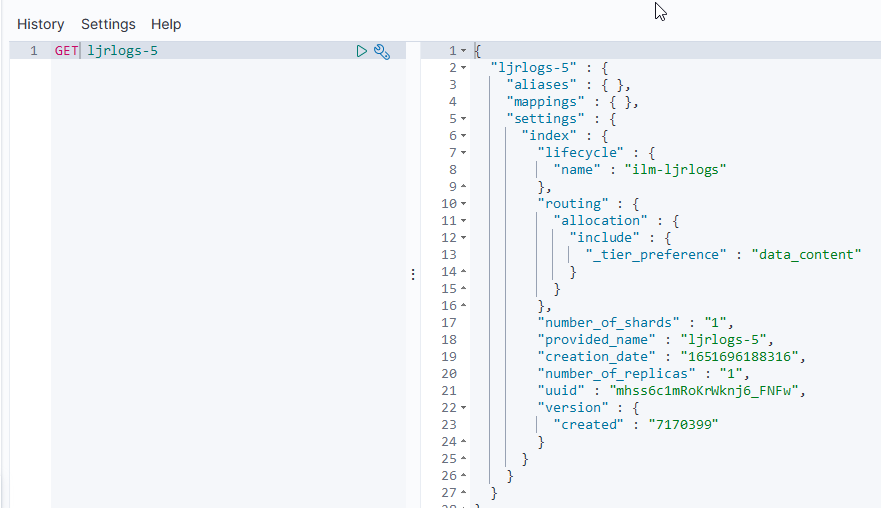
Upon creating a new index (ljrlogs-5), the ILM policy has been applied:
We’re putting up the cheap high tunnel greenhouse that I picked up a few weeks ago.

It took a day to get the frame together.
