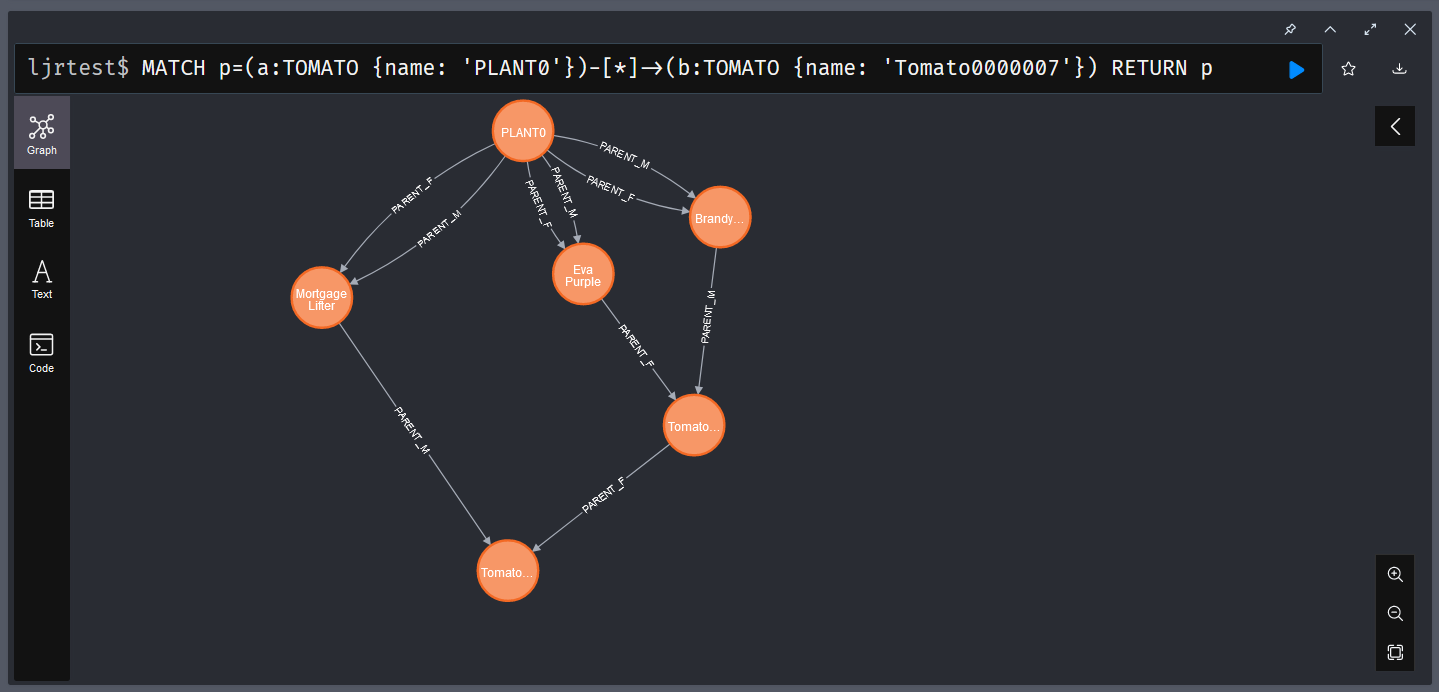
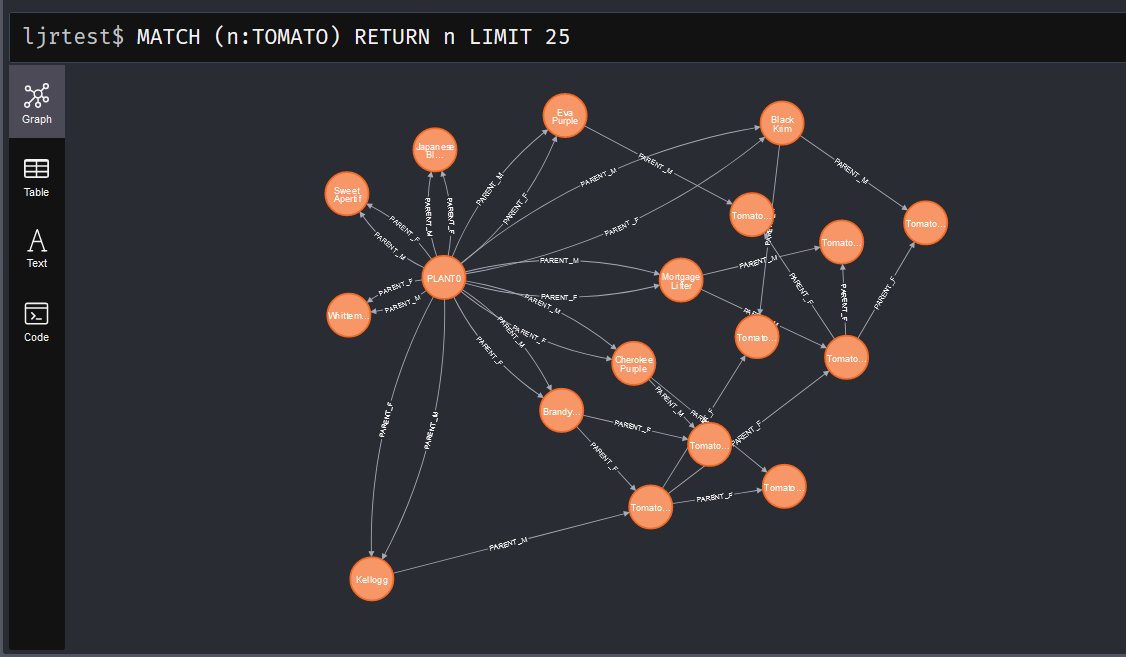
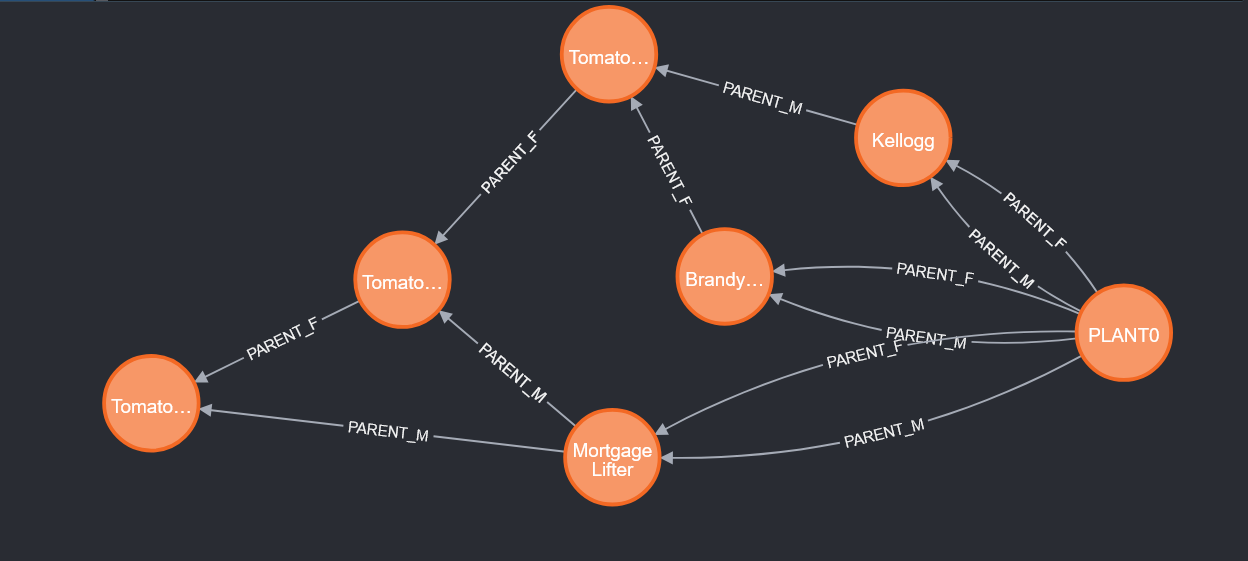
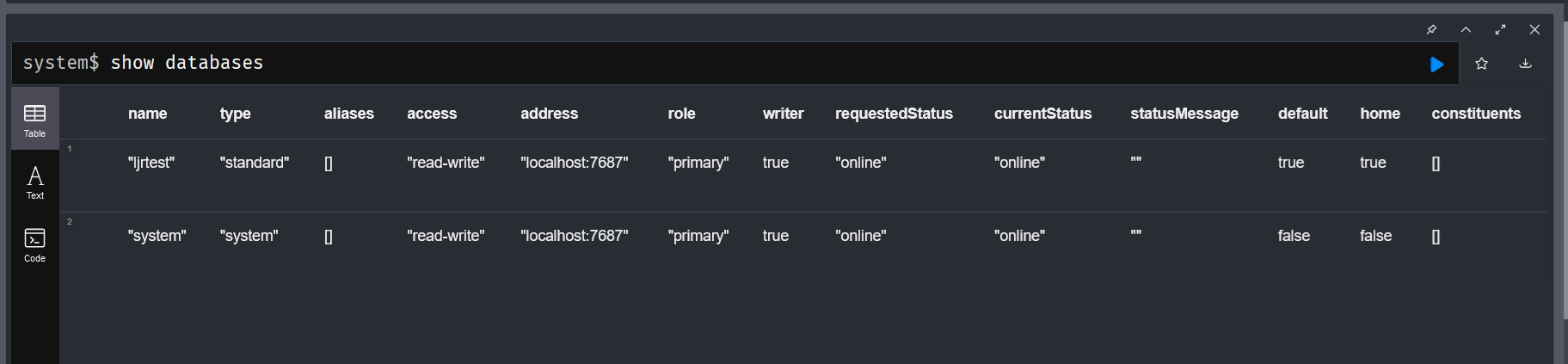
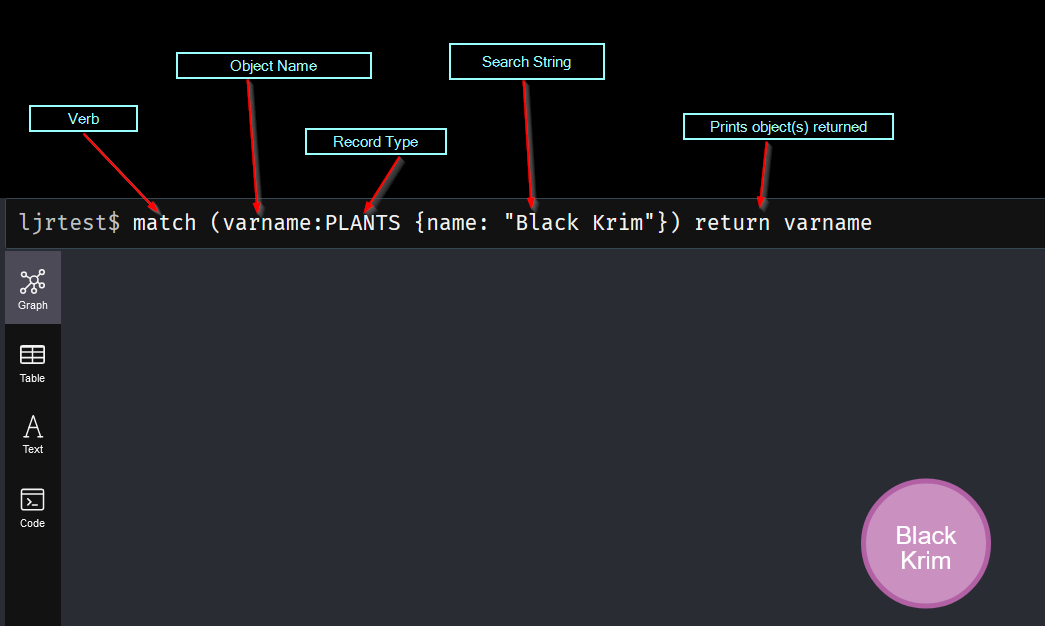
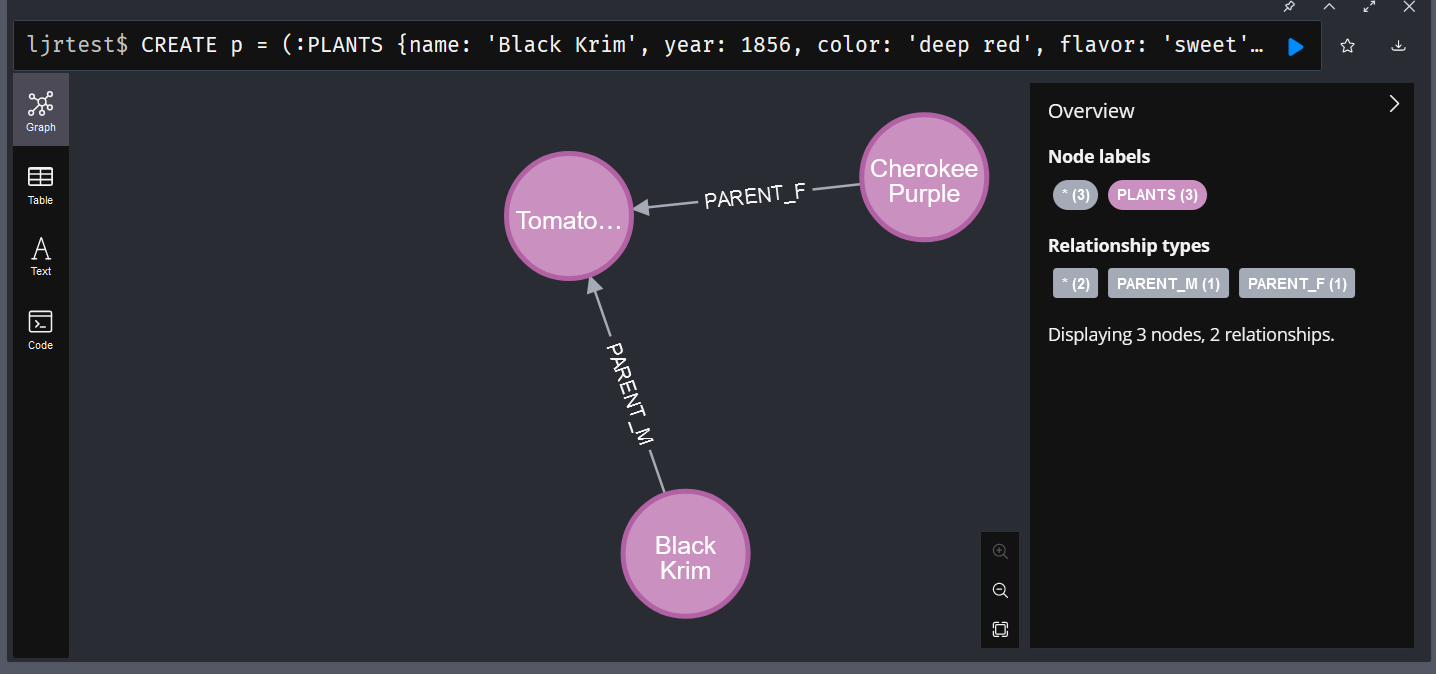
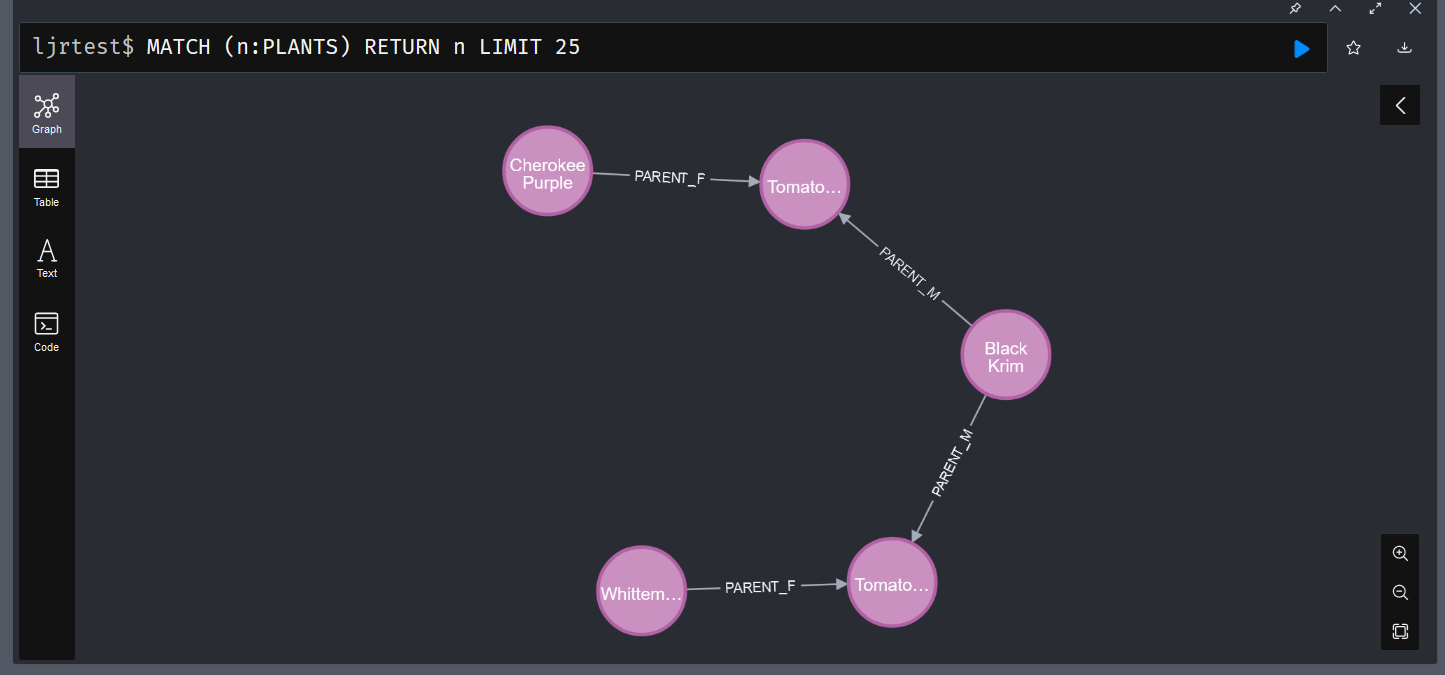
Like SQL-based databases, you can create indices in Neo4j to optimize frequently performed searches. In my particular case, I am usually searching by the plant name. Adding an index on the plant’s name, therefore, makes sense:
CREATE INDEX index_tomato_name IF NOT EXISTS FOR (n:TOMATO) ON (n.name)
I am also interested in mapping the genetic lineage, so I’ve added indices for the male and female parent plants:
CREATE INDEX index_tomato_parentm IF NOT EXISTS for ()-[r:PARENT_M]-() on (r.name) CREATE INDEX index_tomato_parentf IF NOT EXISTS for ()-[r:PARENT_F]-() on (r.name)
Hypothetically, you can use the procedure CALL db.indexes(); to view all of the indices in a database, but SHOW PROCEDURES; shows me that procedure isn’t registered in the community edition.
╒═════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤═══════╤═════════════╕ │name │description │mode │worksOnSystem│ ╞═════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪═══════╪═════════════╡ │"db.awaitIndex" │"Wait for an index to come online (for example: CALL db.awaitIndex(\"M│"READ" │true │ │ │yIndex\", 300))." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.awaitIndexes" │"Wait for all indexes to come online (for example: CALL db.awaitIndexe│"READ" │true │ │ │s(300))." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.clearQueryCaches" │"Clears all query caches." │"DBMS" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.createLabel" │"Create a label" │"WRITE"│false │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.createProperty" │"Create a Property" │"WRITE"│false │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.createRelationshipType" │"Create a RelationshipType" │"WRITE"│false │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.index.fulltext.awaitEventuallyConsistentIndexRefresh"│"Wait for the updates from recently committed transactions to be appli│"READ" │true │ │ │ed to any eventually-consistent full-text indexes." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.index.fulltext.listAvailableAnalyzers" │"List the available analyzers that the full-text indexes can be config│"READ" │true │ │ │ured with." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.index.fulltext.queryNodes" │"Query the given full-text index. Returns the matching nodes, and thei│"READ" │true │ │ │r Lucene query score, ordered by score. Valid keys for the options map│ │ │ │ │ are: 'skip' to skip the top N results; 'limit' to limit the number of│ │ │ │ │ results returned; 'analyzer' to use the specified analyzer as search │ │ │ │ │analyzer for this query." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.index.fulltext.queryRelationships" │"Query the given full-text index. Returns the matching relationships, │"READ" │true │ │ │and their Lucene query score, ordered by score. Valid keys for the opt│ │ │ │ │ions map are: 'skip' to skip the top N results; 'limit' to limit the n│ │ │ │ │umber of results returned; 'analyzer' to use the specified analyzer as│ │ │ │ │ search analyzer for this query." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.info" │"Provides information regarding the database." │"READ" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.labels" │"List all available labels in the database." │"READ" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.ping" │"This procedure can be used by client side tooling to test whether the│"READ" │true │ │ │y are correctly connected to a database. The procedure is available in│ │ │ │ │ all databases and always returns true. A faulty connection can be det│ │ │ │ │ected by not being able to call this procedure." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.prepareForReplanning" │"Triggers an index resample and waits for it to complete, and after th│"READ" │true │ │ │at clears query caches. After this procedure has finished queries will│ │ │ │ │ be planned using the latest database statistics." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.propertyKeys" │"List all property keys in the database." │"READ" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.relationshipTypes" │"List all available relationship types in the database." │"READ" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.resampleIndex" │"Schedule resampling of an index (for example: CALL db.resampleIndex(\│"READ" │true │ │ │"MyIndex\"))." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.resampleOutdatedIndexes" │"Schedule resampling of all outdated indexes." │"READ" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.schema.nodeTypeProperties" │"Show the derived property schema of the nodes in tabular form." │"READ" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.schema.relTypeProperties" │"Show the derived property schema of the relationships in tabular form│"READ" │true │ │ │." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.schema.visualization" │"Visualizes the schema of the data based on available statistics. A ne│"READ" │true │ │ │w node is returned for each label. The properties represented on the n│ │ │ │ │ode include: `name` (label name), `indexes` (list of indexes), and `co│ │ │ │ │nstraints` (list of constraints). A relationship of a given type is re│ │ │ │ │turned for all possible combinations of start and end nodes. The prope│ │ │ │ │rties represented on the relationship include: `name` (type name). Not│ │ │ │ │e that this may include additional relationships that do not exist in │ │ │ │ │the data due to the information available in the count store. " │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.stats.clear" │"Clear collected data of a given data section. Valid sections are 'QUE│"READ" │true │ │ │RIES'" │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.stats.collect" │"Start data collection of a given data section. Valid sections are 'QU│"READ" │true │ │ │ERIES'" │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.stats.retrieve" │"Retrieve statistical data about the current database. Valid sections │"READ" │true │ │ │are 'GRAPH COUNTS', 'TOKENS', 'QUERIES', 'META'" │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.stats.retrieveAllAnonymized" │"Retrieve all available statistical data about the current database, i│"READ" │true │ │ │n an anonymized form." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.stats.status" │"Retrieve the status of all available collector daemons, for this data│"READ" │true │ │ │base." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"db.stats.stop" │"Stop data collection of a given data section. Valid sections are 'QUE│"READ" │true │ │ │RIES'" │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.cluster.routing.getRoutingTable" │"Returns the advertised bolt capable endpoints for a given database, d│"DBMS" │true │ │ │ivided by each endpoint's capabilities. For example an endpoint may se│ │ │ │ │rve read queries, write queries and/or future getRoutingTable requests│ │ │ │ │." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.components" │"List DBMS components and their versions." │"DBMS" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.info" │"Provides information regarding the DBMS." │"DBMS" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.killConnection" │"Kill network connection with the given connection id." │"DBMS" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.killConnections" │"Kill all network connections with the given connection ids." │"DBMS" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.listCapabilities" │"List capabilities" │"DBMS" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.listConfig" │"List the currently active config of Neo4j." │"DBMS" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.listConnections" │"List all accepted network connections at this instance that are visib│"DBMS" │true │ │ │le to the user." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.queryJmx" │"Query JMX management data by domain and name. For instance, \"*:*\"" │"DBMS" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.routing.getRoutingTable" │"Returns the advertised bolt capable endpoints for a given database, d│"DBMS" │true │ │ │ivided by each endpoint's capabilities. For example an endpoint may se│ │ │ │ │rve read queries, write queries and/or future getRoutingTable requests│ │ │ │ │." │ │ │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.upgrade" │"Upgrade the system database schema if it is not the current schema." │"WRITE"│true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"dbms.upgradeStatus" │"Report the current status of the system database sub-graph schema." │"READ" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"tx.getMetaData" │"Provides attached transaction metadata." │"DBMS" │true │ ├─────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────┼─────────────┤ │"tx.setMetaData" │"Attaches a map of data to the transaction. The data will be printed w│"DBMS" │false │ │ │hen listing queries, and inserted into the query log." │ │ │ └─────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────┴