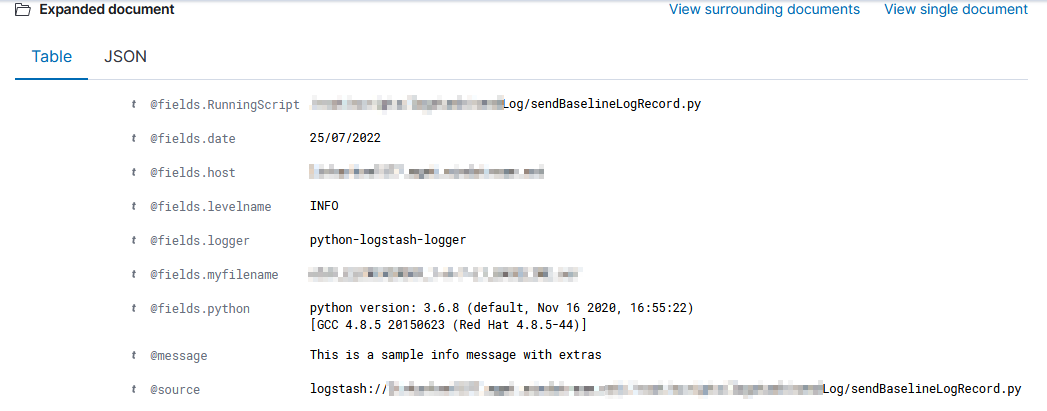
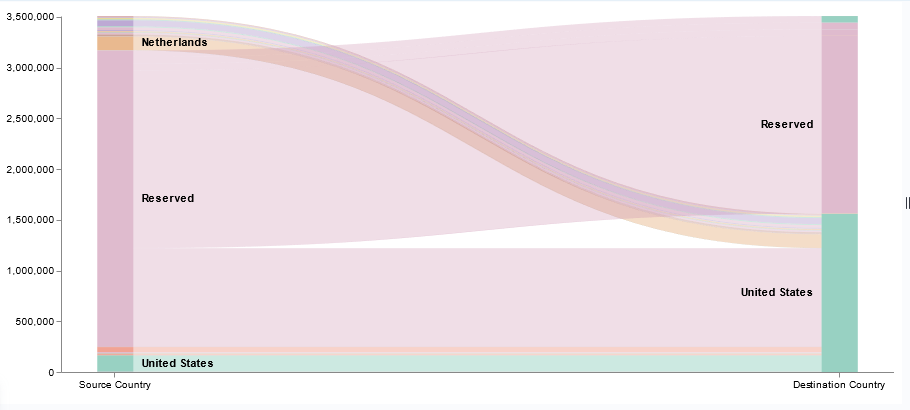
I’ve been working on forking log data into two different indices based on an element contained within the record — if the filename being sent includes the string “BASELINE”, then the data goes into the baseline index, otherwise it goes into the scan index. The data being ingested has the file name in “@fields.myfilename”
It took a while to figure out how to get the value from the current data — event.get(‘[@fields][myfilename]’) to get the @fields.myfilename value.
The following logstash config accepts JSON inputs, parses the underscore-delimited filename into fields, replaces the dashes with underscores as KDL doesn’t handle dashes and wildcards in searches, and adds a flag to any record that should be a baseline. In the output section, that flag is then used to publish data to the appropriate index based on the baseline flag value.
We checked on the bees around noon today. We’ve seen a lot of activity at the hive, and they seem to love the field of clover in our yard — so we were curious to see how much the colony had built up. It wasn’t as full as we were hoping (we would have loved to add a super!). There were more bees in the upper deep than last time, but the hive box wasn’t super full. Maybe five frames with brood, several frames with honey, and a few frames that they’d started drawing out. We moved the frames around — the brood frames were all clustered together, so we moved (2?) frames up to the top deep and interspersed empty and half-empty frames with the full ones. Hopefully having empty frames in the middle will encourage them to build out the frames.
There’s often a difference between hypothetical (e.g. the physics formula answer) and real results — sometimes this is because sciences will ignore “negligible” factors that can be, well, more than negligible, sometimes this is because the “real world” isn’t perfect. In transmission media, this difference is a measurable “loss” — hypothetically, we know we could send X data in Y delta-time, but we only sent X’. Loss also happens because stuff breaks — metal corrodes, critters nest in fiber junction boxes, dirt builds up on a dish. And it’s not easy, when looking at loss data at a single point in time, to identify what’s normal loss and what’s a problem.
We’re starting a project to record a baseline of loss for all sorts of things — this will allow individuals to check the current loss data against that which engineers say “this is as good as it’s gonna get”. If the current value is close … there’s not a problem. If there’s a big difference … someone needs to go fix something.
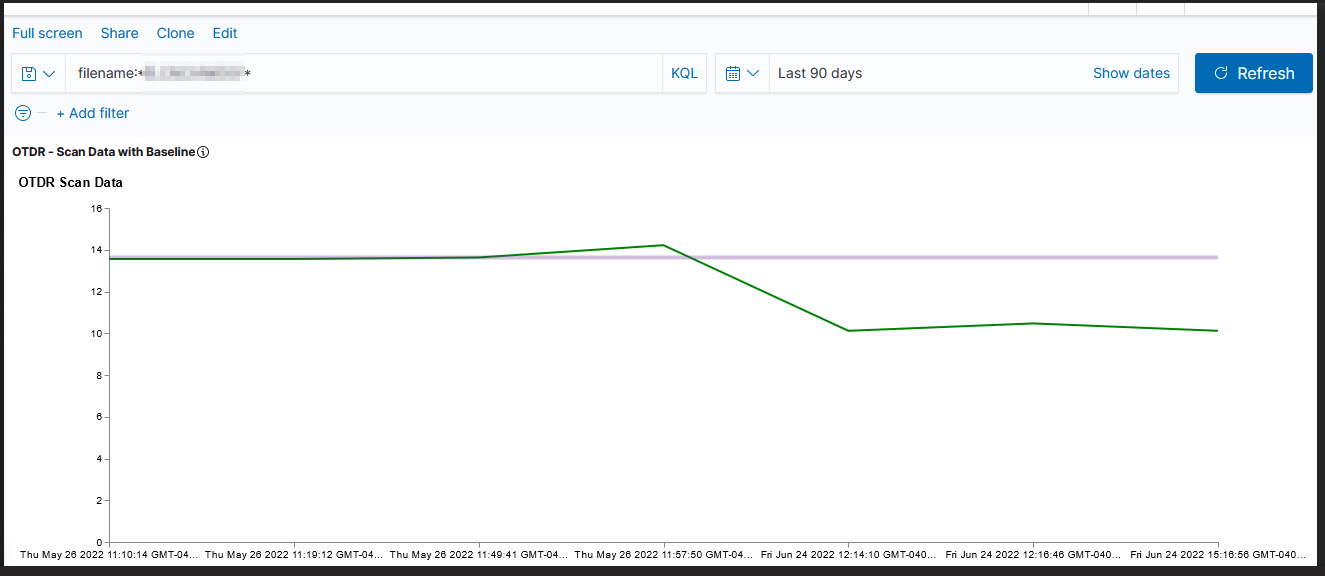
Unfortunately, creating a graph in Kibana that shows the baseline was … not trivial. There is a rule mark that allows you to draw a straight line between two points. You cannot just say “draw a line at y from 0 to some large value that’s going to be off the graph. The line doesn’t render (say, 0 => today or the year 2525). You cannot just get the max value of the axis.
I finally stumbled across a series of data contortions that make the baseline graphable.
The data sets I have available have a datetime object (when we measured this loss) and a loss value. For scans, there may be lots of scans for a single device. For baselines, there will only be one record.
The joinaggregate transformation method — which appends the value to each element of the data set — was essential because I needed to know the largest datetime value that would appear in the chart.
The lookup transformation method — which can access elements from other data sets — allowed me to get that maximum timestamp value into the baseline data set. Except … lookup needs an exact match in the search field. Luckily, it does return a random (I presume either first or last … but it didn’t matter in this case because all records have the same max date value) record when multiple matches are found.
Voila — a chart with a horizontal line at the baseline loss value. Yes, I randomly copied a record to use as the baseline and selected the wrong one (why some scans are below the “good as it’s ever going to get” baseline value!). But … once we have live data coming into the system, we’ll have reasonable looking graphs.
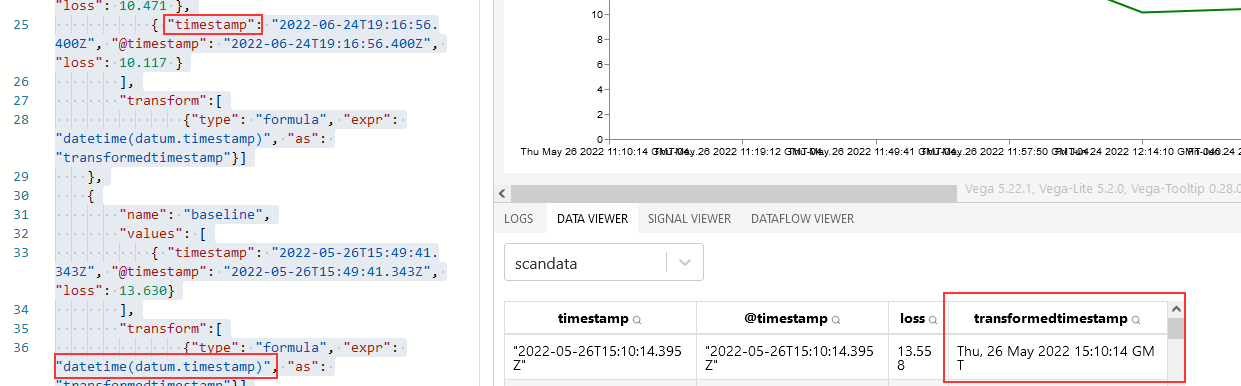
We have data created by an external source (i.e. I cannot just change the names used so it works) — the datetime field is named @timestamp and I had an awful time figuring out out how to address that element within a transformation expression.
Just to make sure I wasn’t doing something silly, I created a copy of the data element named without the at symbol. Voila – transformedtimestamp is populated with a datetime element.
I finally figured it out – it appears that I have encountered a JavaScript limitation. Instead of using the dot-notation to access the element, the array subscript method works – not datum.@timestamp in any iteration or with any combination of escapes.
Preheat oven to 325F. Whisk all ingredients together and pour into individual ramekins. Fill a baking pan with some water, place ramekins into pan. Bake until the custard sets — about 30 minutes.
I got the seeds started for our fall harvested vegetables. We bought these little seed starting trays on Amazon — a tray, a 12-cell insert, and a humidity dome with an adjustable vent. The kit came with plant markers … but it seemed silly to write something permanent on the marker. So I turned them into reusable markers by adding some of the blue tape you use for painting a room (because that’s what we’ve got & pen works OK on it). First I put three of the markers in a line on the tape.
Making plant labels reusable
A couple of quick slices with an Exacto knife, and I can change the label as needed.
When we decided to use some old cinder blocks to build raised beds, the idea was to fill all of the blocks with dirt and use the spaces as bonus planting spaces for small plants like flowers and herbs. Functional and aesthetically pleasing. I never got far in that project — filled some blocks with dirt and lots of weeds. But no ring of herbs around the bed.
This year, I’m doing it! It’s a time consuming process to clear out the existing plant growth. I’m adding about two inches of rocks (we’ve got a lot of rock-covered beds that we want to de-rock), and filling up with soil. Anya started a bunch of herb plants, so she has been transplanting her seedlings into the blocks and adding some wood mulch (I expect these small blocks will warm up and dry out rather quickly otherwise).
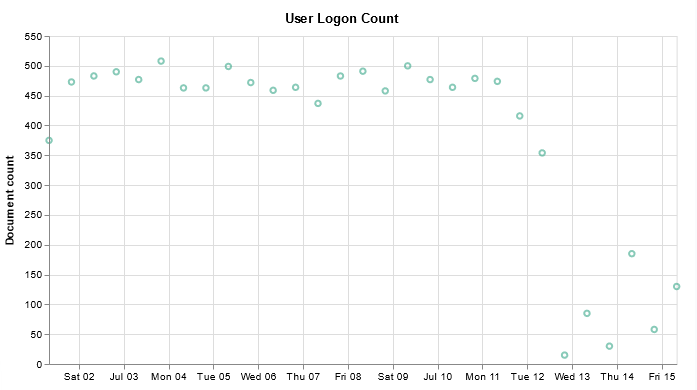
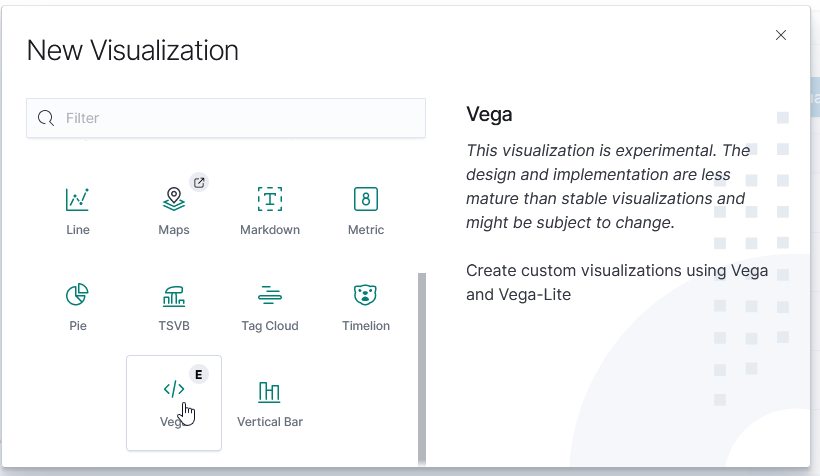
I have finally managed to produce a chart that includes a query — I don’t want to have to walk all of the help desk users through setting up the query, although I figured having the ability to select your own time range would be useful.
{
$schema: https://vega.github.io/schema/vega-lite/v2.json
title: User Logon Count
// Define the data source
data: {
url: {
// Which index to search
index: firewall_logs*
body: {
_source: ['@timestamp', 'user', 'action']
"query": {
"bool": {
"must": [{
"query_string": {
"default_field": "subtype",
"query": "user"
}
},
{
"range": {
"@timestamp": {
"%timefilter%": true
}
}
}]
}
}
aggs: {
time_buckets: {
date_histogram: {
field: @timestamp
interval: {%autointerval%: true}
extended_bounds: {
// Use the current time range's start and end
min: {%timefilter%: "min"}
max: {%timefilter%: "max"}
}
// Use this for linear (e.g. line, area) graphs. Without it, empty buckets will not show up
min_doc_count: 0
}
}
}
size: 0
}
}
format: {property: "aggregations.time_buckets.buckets"}
}
mark: point
encoding: {
x: {
field: key
type: temporal
axis: {title: false} // Don't add title to x-axis
}
y: {
field: doc_count
type: quantitative
axis: {title: "Document count"}
}
}
}
If you open the browser’s developer console, you can access debugging information. This works when you are editing a visualization as well as when you are viewing one. To see a list of available functions, type VEGA_DEBUG. and a drop-down will show you what’s available. The command “VEGA_DEBUG.vega_spec” outputs pretty much everything about the chart.
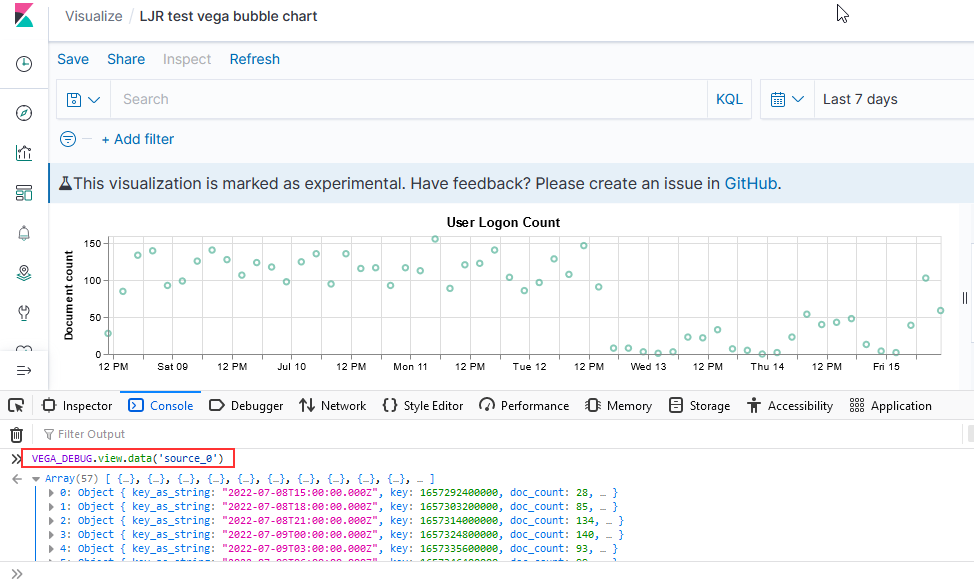
To access the data set being graphed with the Vega Lite grammar, use “VEGA_DEBUG.view.data(“source_0)” — if you are using the Vega grammar, use the dataset name that you have defined.
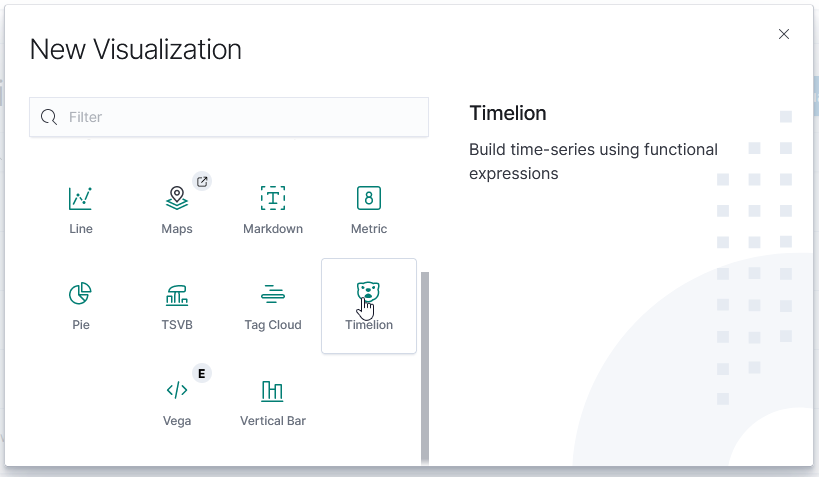
To create a new visualization, select the visualization icon from the left-hand navigation menu and click “Create visualization”. You’ll need to select the type of visualization you want to create.
TSVB (Time Series Visualization Builder)
The Time Series Visualization Pipeline is a GUI visualization builder to create graphs from time series data. This means the x-axis will be datetime values and the y-axis will the data you want to visualize over the time period. To create a new visualization of this type, select “TSVB” on the “New Visualization” menu.
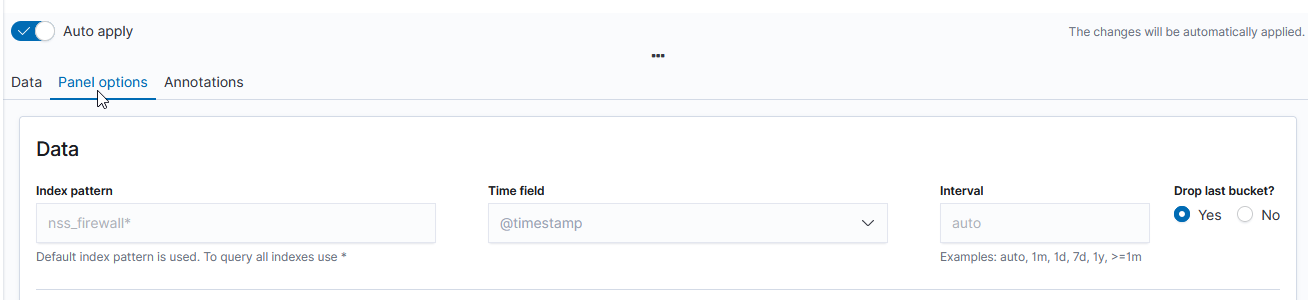
Scroll down and select “Panel options” – here you specify the index you want to visualize. Select the field that will be used as the time for each document (e.g. if your document has a special field like eventOccuredAt, you’d select that here). I generally leave the time interval at ‘auto’ – although you might specifically want to present a daily or hourly report.
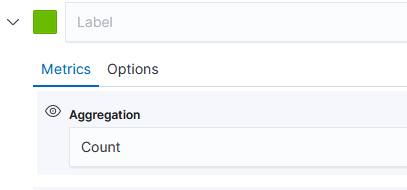
Once you have selected the index, return to the “Data” tab. First, select the type of aggregation you want to use. In this example, we are showing the number of documents for a variety of policies.
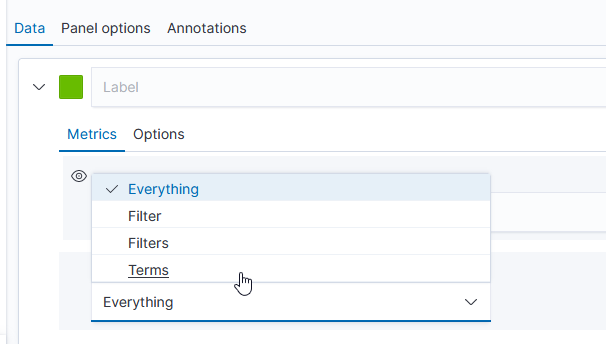
The “Group by” dropdown allows you to have chart lines for different categories (instead of just having the count of documents over the time series, which is what “Everything” produces) – to use document data to create the groupings, select “Terms”.
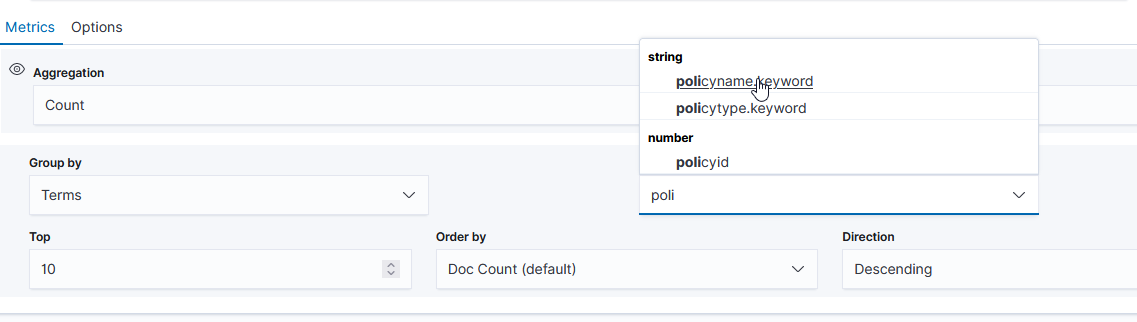
Select the field you want to group on – in this case, I want the count for each unique “policyname” value, so I selected “policyname.keyword” as the grouping term.
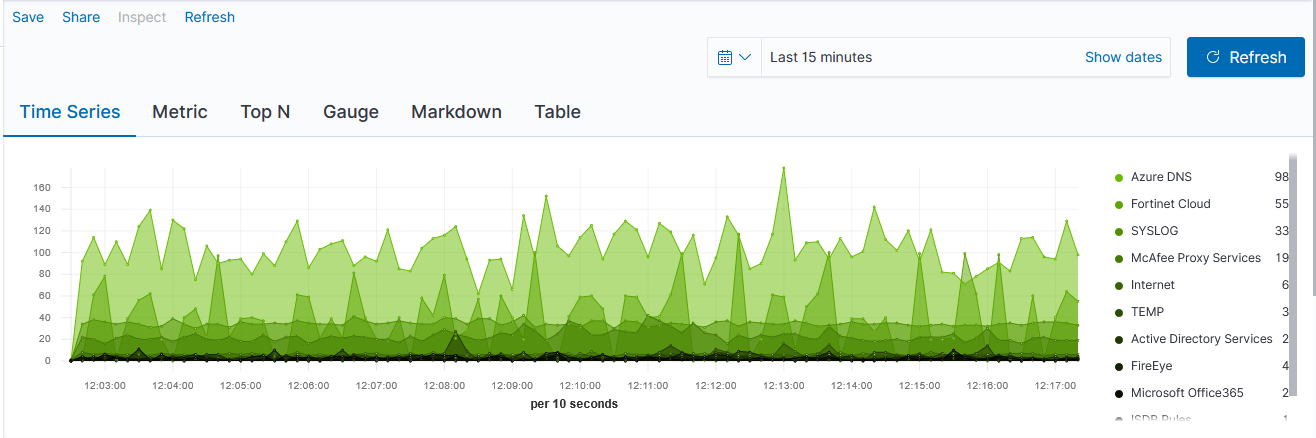
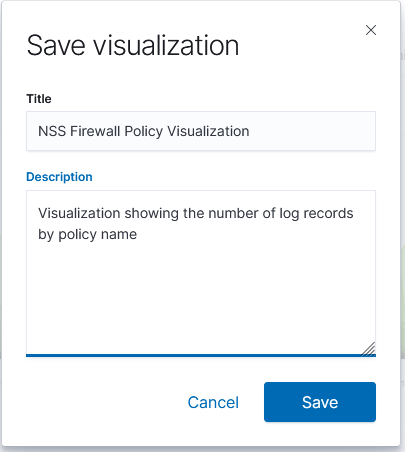
Voila – a time series chart showing how many documents are found for each policy name. Click “Save” at the top left of the chart to save the visualization.
Provide a name for the visualization, write a brief description, and click “Save”. The visualization will now be available for others to view or for inclusion in dashboards.
TimeLion
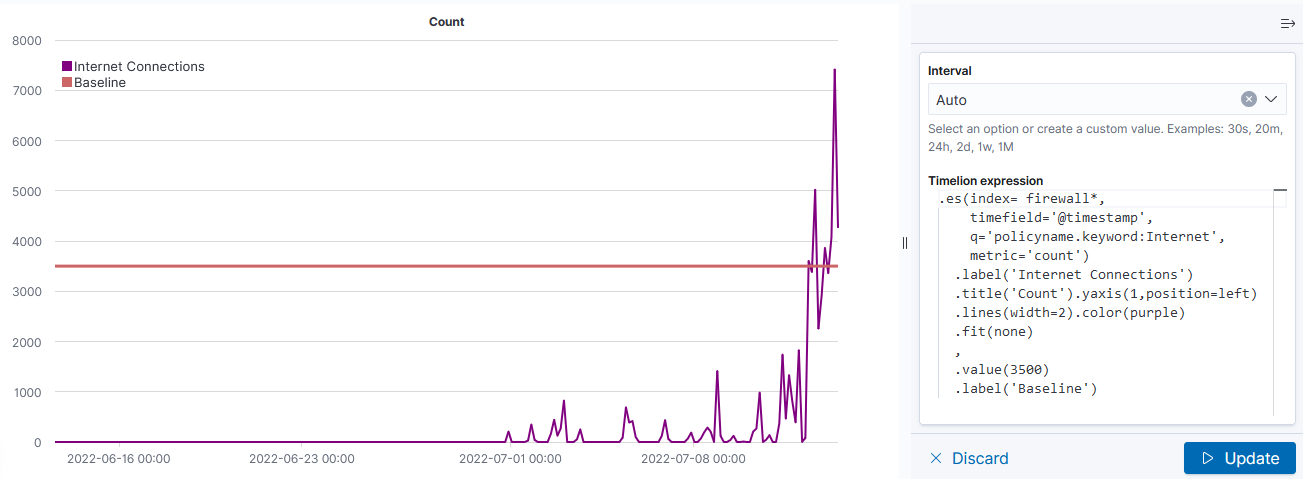
TimeLion looks like it is going away soon, but it’s what I’ve seen as the recommendation for drawing horizontal lines on charts.
This visualization type is a little cryptic – you need to enter Timelion expression — .es() retrieves data from ElasticSearch, .value(3500) draws a horizontal line at 3,500
If there is null data at a time value, TimeLion will draw a discontinuous line. You can modify this behavior by specifying a fit function.
Note that you’ll need to click “Update” to update the chart before you are able to save the visualization.