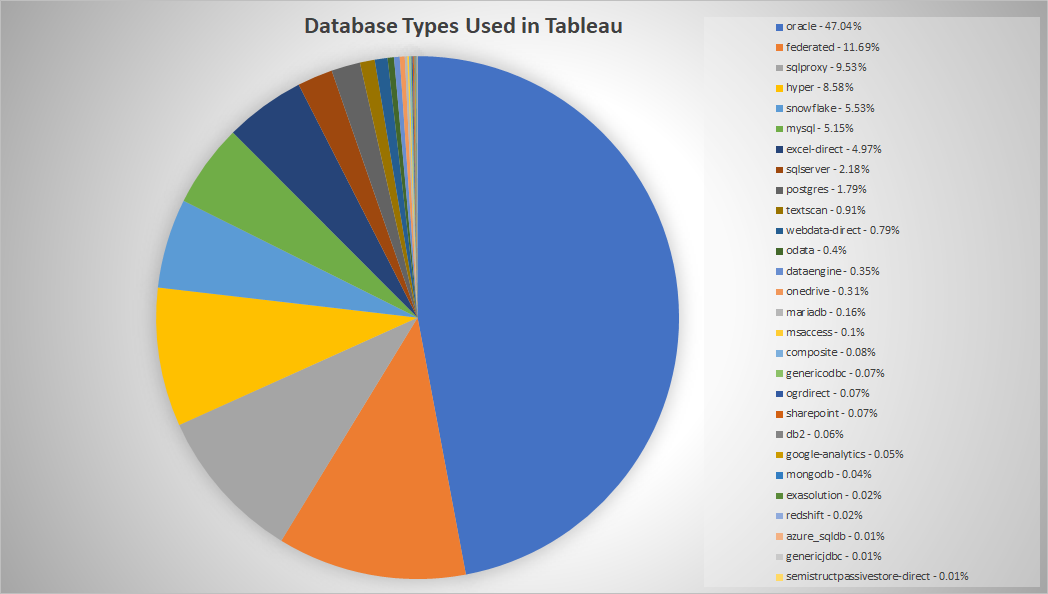
While I am certain table-based SQL databases required planning to establish a reasonable data model – optimizing storage, defining foreign keys, indexing … I have found it more challenging to create a good data model in Neo4j. Maybe that’s because I normally populate SQL tables with custom scripts that can be modified to handle all sorts of edge cases. Maybe I’m still thinking in tables, but there seems to be more trial and error in defining the data model than I’ve ever had in SQL databases.
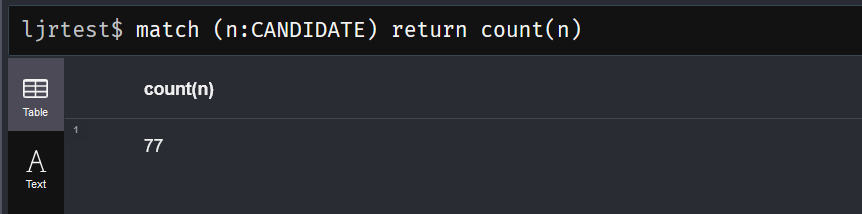
In the import-from-html-table example, a candidate often is associated with multiple elections. Storing candidates as nodes and elections as other nodes that contain results (electoral college votes for winner & loser and popular votes for winner & loser) then associating candidates with elections allowed me to store data about US elections in the Graph. I know who ran, who won and who lost, and what the results were for each election.
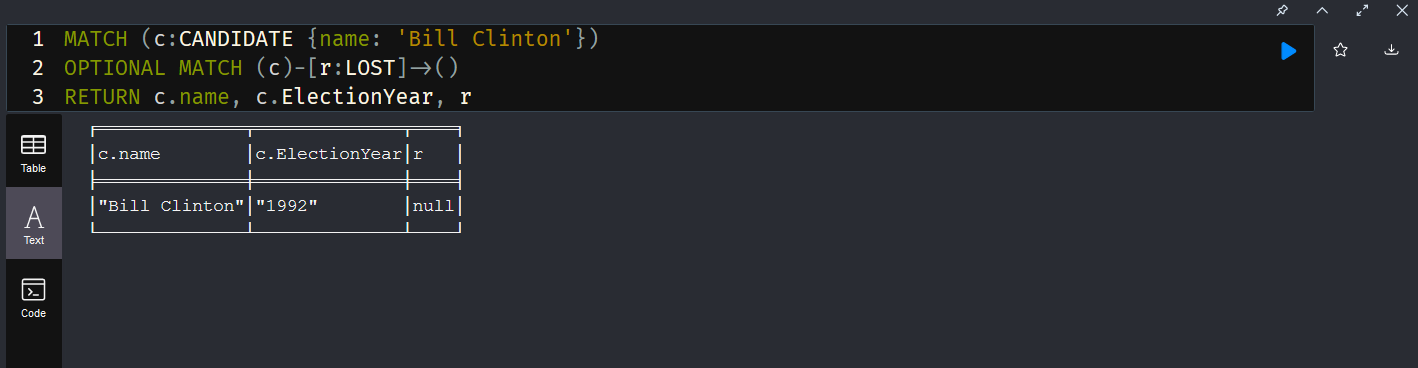
Associating the results with candidates didn’t work because Franklin D Roosevelt only has one property for “EC_VOTES” … which election does that reflect? I could also have added the vote totals to the relationship but that would either separate the data (the loser’s votes are stored on LOST relationships and the winner’s are stored on WON relationships) or data duplication (both WON and LOST relationships contain the same vote numbers).
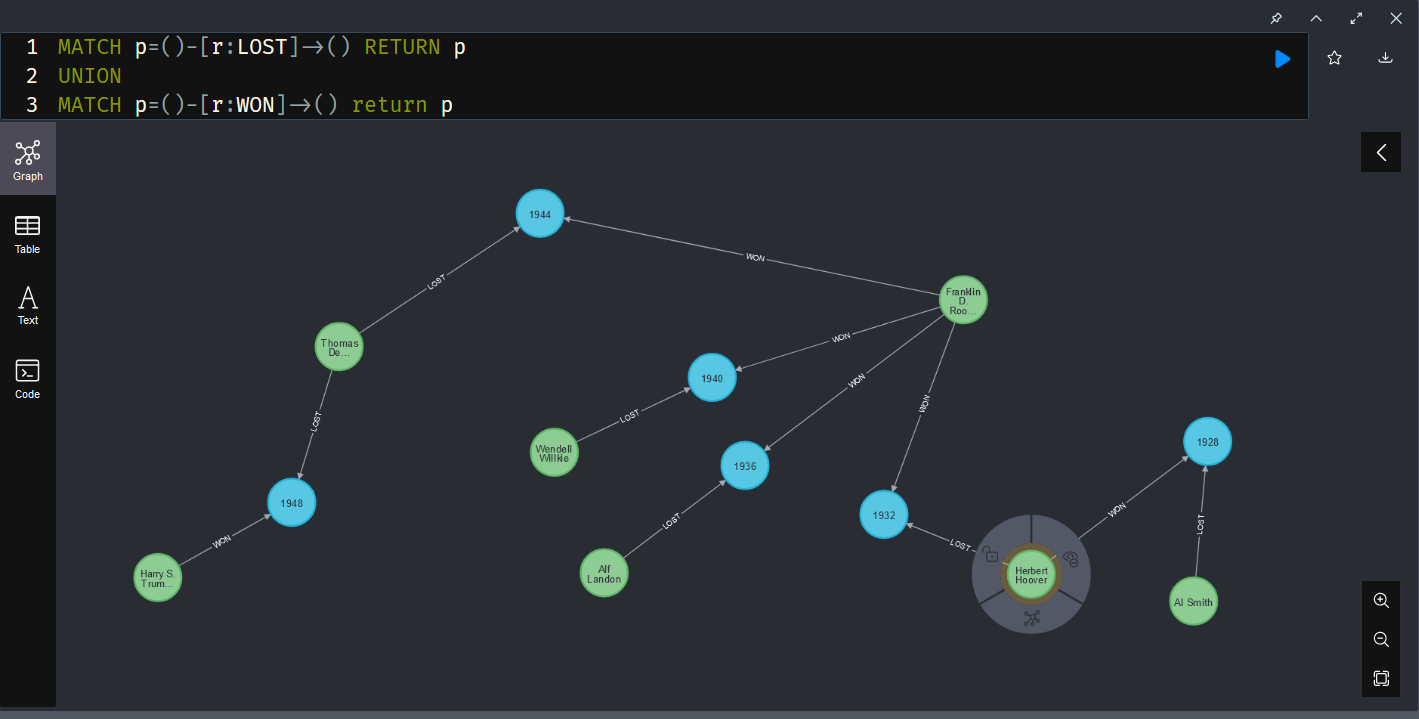
Query used to populate the data:
CALL apoc.load.html("https://www.iweblists.com/us/government/PresidentialElectionResults.html",
{electionyear: "#listtable tbody tr td:eq(0)"
, winner: "#listtable tbody tr td:eq(1)"
, loser: "#listtable tbody tr td:eq(2)"
, electoral_win: "#listtable tbody tr td:eq(3)"
, electoral_lose: "#listtable tbody tr td:eq(4)"
, popular_win: "#listtable tbody tr td:eq(5)"
, popular_delta: "#listtable tbody tr td:eq(6)" }) yield value
WITH value, size(value.electionyear) as rangeup
UNWIND range(0,rangeup) as i WITH value.electionyear[i].text as ElectionYear
, value.winner[i].text as Winner, value.loser[i].text as Loser
, value.electoral_win[i].text as EC_Winner, value.electoral_lose[i].text as EC_Loser
, value.popular_win[i].text as Pop_Vote_Winner
, value.popular_delta[i].text as Pop_Vote_Margin
MERGE (election:Election {year: coalesce(ElectionYear,"Unknown")})
SET election.EC_Votes_Winner = coalesce(EC_Winner,"Unknown")
SET election.EC_Votes_Loser = coalesce(EC_Loser,"Unknown")
SET election.Pop_Votes_Winner = apoc.text.replace(Pop_Vote_Winner, ",", "")
SET election.Pop_Votes_Loser = apoc.number.exact.sub(apoc.text.replace(Pop_Vote_Winner, ",", ""), apoc.text.replace(Pop_Vote_Margin, ",", ""))
MERGE (ew:CANDIDATE {name: coalesce(Winner,"Unknown")})
MERGE (el:CANDIDATE {name: coalesce(Loser,"Unknown")})
MERGE (ew)-[:WON]->(election) MERGE (el)-[:LOST]->(election);