I encountered an oddity in a Java application that uses Kafka Streams to implement a scalable application that reads data from Kafka topics. Data is broken out into multiple topics, and there are Kubernetes pods (“workers”) reading from each topic. The pods have different numbers of replicas defined. But it appears that no one ever aligned the topic partitions with the number of workers being deployed.
Kafka Streams assigns “work” to group members by partition. If you have ten partitions and five workers, each worker processes the data from two partitions. However, when the numbers don’t line up … some workers get more partitions than others. Were you to have eleven partitions and five workers, four workers would get data from two partitions and the fifth worker gets data from three.
Worse – in some cases we have more workers than partitions. Those extra workers are using up some resources, but they’re not actually processing data.
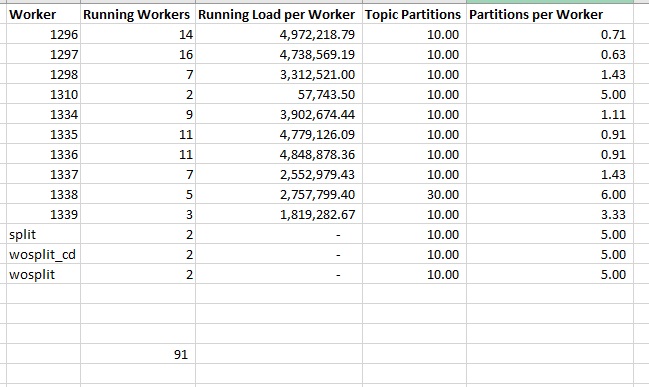
It’s a quick fix — partitions can be added mostly invisibly (the consumer group will be re-balanced, write operations won’t really change. New data just starts getting placed in the new partitions), so I increased our partition counts to be 2x the number of workers. This allows us to add a few workers to a topic if it gets backlogged, but the configuration evenly distributes the work across all of the normally running pods.