Our ElasticSearch environment melted down in a fairly spectacular fashion — evidently (at least in older iterations), it’s an unhandled Java exception when a server is trying to send data over to another server that is refusing it because that would put the receiver over the shard limit. So we didn’t just have a server or three go into read only mode — we had cascading failure where java would except out and the process was dead. Restarting the ElasticSearch service temporarily restored functionality — so I quickly increased the max shards per node limit to keep the system up whilst I cleaned up whatever I could clean up
curl -X PUT http://uid:pass@`hostname`:9200/_cluster/settings -H "Content-Type: application/json" -d '{ "persistent": { "cluster.max_shards_per_node": "5000" } }'
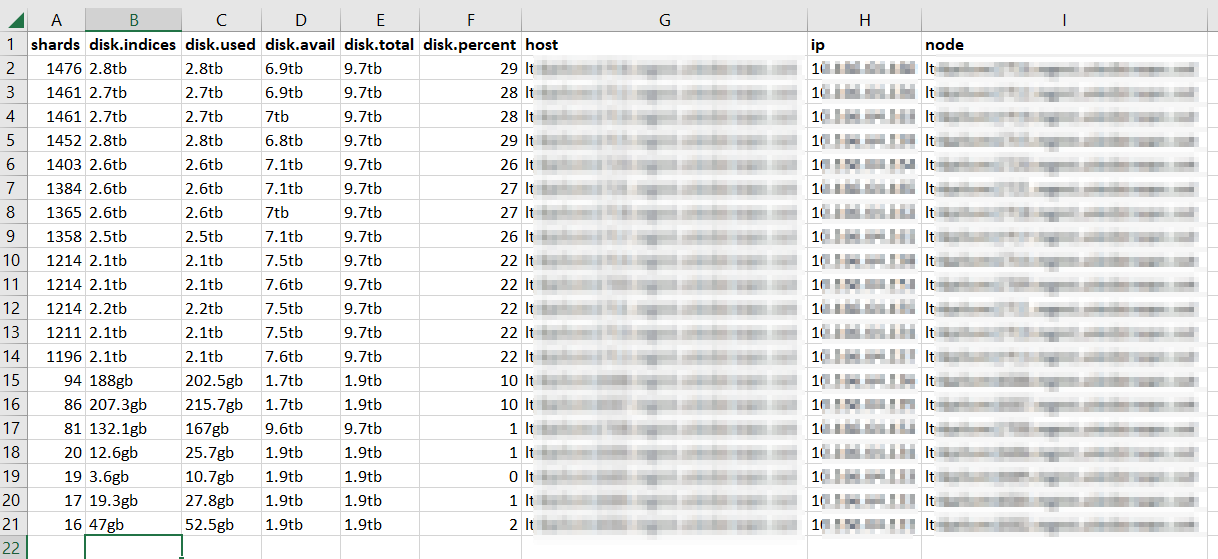
There were two requests against the ES API that were helpful in cleaning ‘stuff’ up — GET /_cat/allocation?v returns a list of each node in the ES cluster with a count of shards (plus disk space) being used. This was useful in confirming that load across ‘hot’, ‘warm’, and ‘cold’ nodes was reasonable. If it was not, we would want to investigate why some nodes were under-allocated. We were, however, fine.
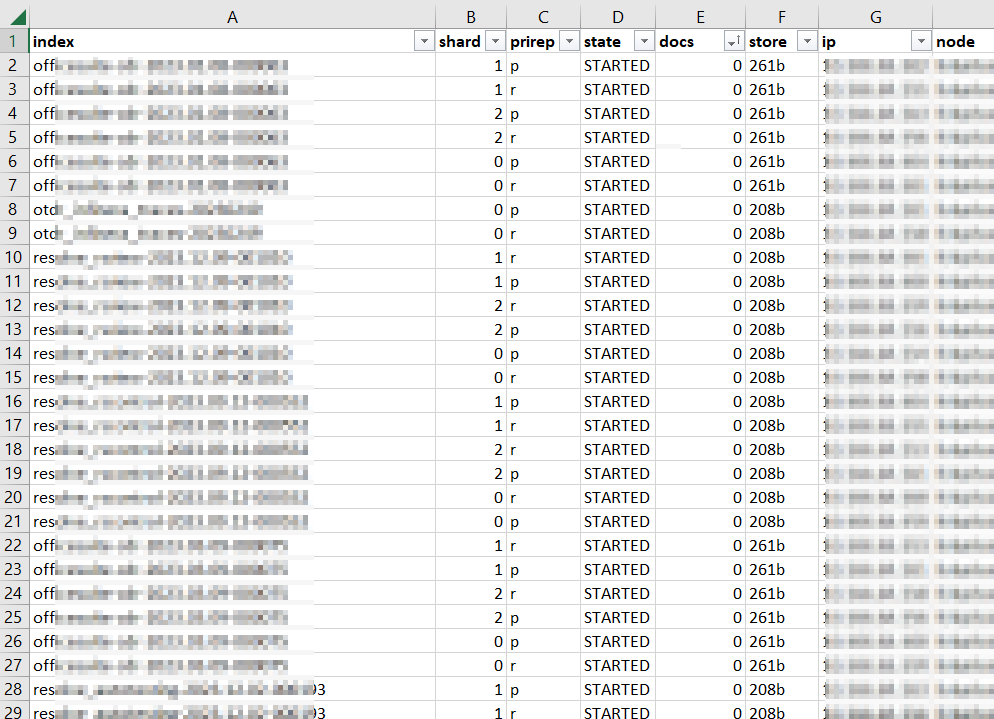
The second request: GET /_cat/shards?v=true which dumps out all of the shards that comprise the stored data. In my case, a lot of clients create a new index daily — MyApp-20231215 — and then proceeded to add absolutely nothing to that index. Literally 10% of our shards were devoted to storing zero documents! Well, that’s silly. I created a quick script to remove any zero-document index that is older than a week. A new document coming in will create the index again, and we don’t need to waste shards not storing data.
Once you’ve cleaned up the shards, it’s a good idea to drop your shard-per-node configuration down again. I’m also putting together a script to run through the allocated shards per node data to alert us when allocation is unbalanced or when total shards approach our limit. Hopefully this will allow us to proactively reduce shards instead of having the entire cluster fall over one night.